使用Python,从字符串中剥离所有非字母数字字符的最佳方法是什么?
在此问题的PHP变体中提供的解决方案可能需要进行一些微调,但对我来说似乎不太“pythonic”。
记录一下,我不仅想去掉句号、逗号(和其他标点符号),还想去掉引号、括号等。
使用Python,从字符串中剥离所有非字母数字字符的最佳方法是什么?
在此问题的PHP变体中提供的解决方案可能需要进行一些微调,但对我来说似乎不太“pythonic”。
记录一下,我不仅想去掉句号、逗号(和其他标点符号),还想去掉引号、括号等。
我只是出于好奇计时了一些函数。在这些测试中,我从内置的string模块的string.printable字符串中删除非字母数字字符。使用编译后的'[\W_]+'和pattern.sub('', str)方法被发现是最快的。
$ python -m timeit -s \
"import string" \
"''.join(ch for ch in string.printable if ch.isalnum())"
10000 loops, best of 3: 57.6 usec per loop
$ python -m timeit -s \
"import string" \
"filter(str.isalnum, string.printable)"
10000 loops, best of 3: 37.9 usec per loop
$ python -m timeit -s \
"import re, string" \
"re.sub('[\W_]', '', string.printable)"
10000 loops, best of 3: 27.5 usec per loop
$ python -m timeit -s \
"import re, string" \
"re.sub('[\W_]+', '', string.printable)"
100000 loops, best of 3: 15 usec per loop
$ python -m timeit -s \
"import re, string; pattern = re.compile('[\W_]+')" \
"pattern.sub('', string.printable)"
100000 loops, best of 3: 11.2 usec per loop
valid_characters = string.ascii_letters + string.digits并跟随join(ch for ch in string.printable if ch in valid_characters)),它比使用isalnum()选项快6微秒。但仍然比正则表达式慢得多。 - DrAlre.compile('[\W_]+', re.UNICODE)来保证Unicode安全。 - Mark van Lentfilter 的第二种解决方案返回的是一个过滤器对象,而不是一个字符串。还需要将其连接起来。 - physicalattraction利用正则表达式解决问题:
import re
re.sub(r'\W+', '', your_string)
'\W == [^a-zA-Z0-9_],即排除所有数字、字母和_。\W会同时保留下划线。 - Blixtstr.translate() 方法。Once, create a string containing all the characters you wish to delete:
delchars = ''.join(c for c in map(chr, range(256)) if not c.isalnum())
Whenever you want to scrunch a string:
scrunched = s.translate(None, delchars)
re.compile更有优势;边际成本要低得多:C:\junk>\python26\python -mtimeit -s"import string;d=''.join(c for c in map(chr,range(256)) if not c.isalnum());s=string.printable" "s.translate(None,d)"
100000 loops, best of 3: 2.04 usec per loop
C:\junk>\python26\python -mtimeit -s"import re,string;s=string.printable;r=re.compile(r'[\W_]+')" "r.sub('',s)"
100000 loops, best of 3: 7.34 usec per loop
string.printable作为基准数据会使模式'[\W_]+'具有不公平的优势;所有非字母数字字符都在一起...在典型数据中,可能需要进行多次替换:C:\junk>\python26\python -c "import string; s = string.printable; print len(s),repr(s)"
100 '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
如果您让re.sub做更多的工作,会发生以下情况:
C:\junk>\python26\python -mtimeit -s"d=''.join(c for c in map(chr,range(256)) if not c.isalnum());s='foo-'*25" "s.translate(None,d)"
1000000 loops, best of 3: 1.97 usec per loop
C:\junk>\python26\python -mtimeit -s"import re;s='foo-'*25;r=re.compile(r'[\W_]+')" "r.sub('',s)"
10000 loops, best of 3: 26.4 usec per loop
string.punctuation 而不是 ''.join(c for c in map(chr, range(256)) if not c.isalnum())。 - ArnauOrriolsstr 对象而不是 unicode 对象。 - Yavarprint ''.join(ch for ch in some_string if ch.isalnum())
>>> import re
>>> string = "Kl13@£$%[};'\""
>>> pattern = re.compile('\W')
>>> string = re.sub(pattern, '', string)
>>> print string
Kl13
你觉得这个怎么样:
def ExtractAlphanumeric(InputString):
from string import ascii_letters, digits
return "".join([ch for ch in InputString if ch in (ascii_letters + digits)])
使用列表推导式生成一个包含 InputString 中存在于组合的ascii_letters和digits字符串中的字符的列表,然后将列表合并为一个字符串。
我用perfplot(我的一个项目)检查了结果,并发现对于短字符串,
"".join(filter(str.isalnum, s))
对于长字符串(200+字符),它是最快的。
re.sub("[\W_]", "", s)
速度最快。
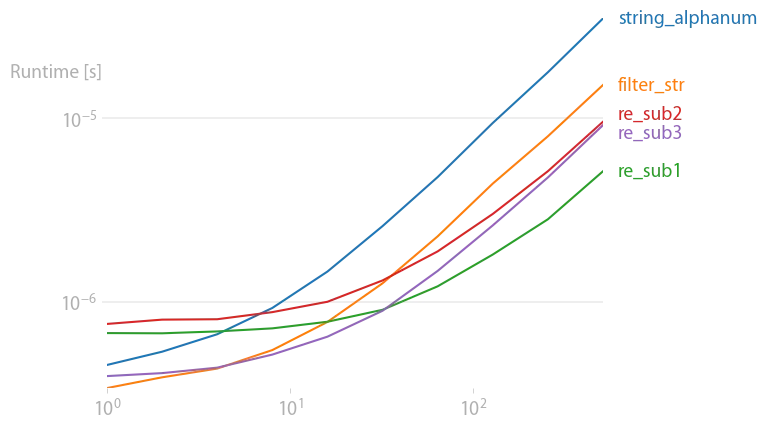
复制代码以重现绘图:
import perfplot
import random
import re
import string
pattern = re.compile("[\W_]+")
def setup(n):
return "".join(random.choices(string.ascii_letters + string.digits, k=n))
def string_alphanum(s):
return "".join(ch for ch in s if ch.isalnum())
def filter_str(s):
return "".join(filter(str.isalnum, s))
def re_sub1(s):
return re.sub("[\W_]", "", s)
def re_sub2(s):
return re.sub("[\W_]+", "", s)
def re_sub3(s):
return pattern.sub("", s)
b = perfplot.bench(
setup=setup,
kernels=[string_alphanum, filter_str, re_sub1, re_sub2, re_sub3],
n_range=[2**k for k in range(10)],
)
b.save("out.png")
b.show()
sent = "".join(e for e in sent if e.isalpha())
e for e in sent 遍历所有字符串字符,并通过 if e.isalpha() 语句检查当前字符是否为字母符号,如果是,则通过 sent = "".join() 将其连接到 sent 变量上,而所有非字母符号将因为 join 函数而被替换为 ""(空字符串)。 - Sysanine.alnum()。 - Vishal Kumar Sahu使用ASCII可打印字符的随机字符串进行计时:
from inspect import getsource
from random import sample
import re
from string import printable
from timeit import timeit
pattern_single = re.compile(r'[\W]')
pattern_repeat = re.compile(r'[\W]+')
translation_tb = str.maketrans('', '', ''.join(c for c in map(chr, range(256)) if not c.isalnum()))
def generate_test_string(length):
return ''.join(sample(printable, length))
def main():
for i in range(0, 60, 10):
for test in [
lambda: ''.join(c for c in generate_test_string(i) if c.isalnum()),
lambda: ''.join(filter(str.isalnum, generate_test_string(i))),
lambda: re.sub(r'[\W]', '', generate_test_string(i)),
lambda: re.sub(r'[\W]+', '', generate_test_string(i)),
lambda: pattern_single.sub('', generate_test_string(i)),
lambda: pattern_repeat.sub('', generate_test_string(i)),
lambda: generate_test_string(i).translate(translation_tb),
]:
print(timeit(test), i, getsource(test).lstrip(' lambda: ').rstrip(',\n'), sep='\t')
if __name__ == '__main__':
main()
结果(Python 3.7):
Time Length Code
6.3716264850008880 00 ''.join(c for c in generate_test_string(i) if c.isalnum())
5.7285426190064750 00 ''.join(filter(str.isalnum, generate_test_string(i)))
8.1875841680011940 00 re.sub(r'[\W]', '', generate_test_string(i))
8.0002205439959650 00 re.sub(r'[\W]+', '', generate_test_string(i))
5.5290945199958510 00 pattern_single.sub('', generate_test_string(i))
5.4417179649972240 00 pattern_repeat.sub('', generate_test_string(i))
4.6772285089973590 00 generate_test_string(i).translate(translation_tb)
23.574712151996210 10 ''.join(c for c in generate_test_string(i) if c.isalnum())
22.829975890002970 10 ''.join(filter(str.isalnum, generate_test_string(i)))
27.210196289997840 10 re.sub(r'[\W]', '', generate_test_string(i))
27.203713296003116 10 re.sub(r'[\W]+', '', generate_test_string(i))
24.008979928999906 10 pattern_single.sub('', generate_test_string(i))
23.945240008994006 10 pattern_repeat.sub('', generate_test_string(i))
21.830899796994345 10 generate_test_string(i).translate(translation_tb)
38.731336012999236 20 ''.join(c for c in generate_test_string(i) if c.isalnum())
37.942474347000825 20 ''.join(filter(str.isalnum, generate_test_string(i)))
42.169366310001350 20 re.sub(r'[\W]', '', generate_test_string(i))
41.933375883003464 20 re.sub(r'[\W]+', '', generate_test_string(i))
38.899814646996674 20 pattern_single.sub('', generate_test_string(i))
38.636144253003295 20 pattern_repeat.sub('', generate_test_string(i))
36.201238164998360 20 generate_test_string(i).translate(translation_tb)
49.377356811004574 30 ''.join(c for c in generate_test_string(i) if c.isalnum())
48.408927293996385 30 ''.join(filter(str.isalnum, generate_test_string(i)))
53.901889764994850 30 re.sub(r'[\W]', '', generate_test_string(i))
52.130339455994545 30 re.sub(r'[\W]+', '', generate_test_string(i))
50.061149017004940 30 pattern_single.sub('', generate_test_string(i))
49.366573111998150 30 pattern_repeat.sub('', generate_test_string(i))
46.649754120997386 30 generate_test_string(i).translate(translation_tb)
63.107938601999194 40 ''.join(c for c in generate_test_string(i) if c.isalnum())
65.116287978999030 40 ''.join(filter(str.isalnum, generate_test_string(i)))
71.477421126997800 40 re.sub(r'[\W]', '', generate_test_string(i))
66.027950693998720 40 re.sub(r'[\W]+', '', generate_test_string(i))
63.315361931003280 40 pattern_single.sub('', generate_test_string(i))
62.342320287003530 40 pattern_repeat.sub('', generate_test_string(i))
58.249303059004890 40 generate_test_string(i).translate(translation_tb)
73.810345625002810 50 ''.join(c for c in generate_test_string(i) if c.isalnum())
72.593953348005020 50 ''.join(filter(str.isalnum, generate_test_string(i)))
76.048324580995540 50 re.sub(r'[\W]', '', generate_test_string(i))
75.106637657001560 50 re.sub(r'[\W]+', '', generate_test_string(i))
74.681338128997600 50 pattern_single.sub('', generate_test_string(i))
72.430461594005460 50 pattern_repeat.sub('', generate_test_string(i))
69.394243567003290 50 generate_test_string(i).translate(translation_tb)
str.maketrans和str.translate是最快的,但包含所有非ASCII字符。re.compile和pattern.sub比较慢,但比''.join和filter要快。
PERMITTED_CHARS中的字符即可。PERMITTED_CHARS = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-"
someString = "".join(c for c in someString if c in PERMITTED_CHARS)
string.digits + string.ascii_letters + '_-'来代替。 - Reti43SPECIAL_CHARS = '_-',然后使用 string.digits + string.ascii_letters + SPECIAL_CHARS。 - BuvinJ