首先,我们可以推导出一个无向图,其中顶点是向量v的元素,边缘是不超过r的点对。这不需要距离成为一个适当的度量:它不必满足三角不等式,只需对称(dist(a,b) == dist(b,a))并且为0,如果两个点相等。
在完成这一步之后,我们可以完全忽略距离,并专注于对图进行分区。正如其他人所指出的那样,该分区是一个Vertex Cover问题。但是,它有一个扭曲的地方:我们要求覆盖中的所有顶点都是不相交的(即:v1中的向量不能彼此在距离r以内)。
为了获得图形,我们可以使用高效的KDTree仅计算一次最近邻结构。特别地,我们将使用kd.sparse_distance_matrix(kd, r)来获取所有距离小于r的点对:
from scipy.spatial import KDTree
def get_graph(v, r):
kd = KDTree(v)
sm = kd.sparse_distance_matrix(kd, r)
graph = {i: {i} for i, _ in sm.keys()}
for i, j in sm.keys():
graph[i] |= {j}
return graph
(注意:如果我们想要使用其他距离,.sparse_distance_matrix()有一个参数p)。
图的分区可以通过多种方式完成。@DanR展示了一种贪婪的方法,非常快速,但通常在找到v1的大小时不够优秀。
下面展示了一种暴力方法,如果存在最小解,则保证找到最小解。对于相对较少的向量来说是足够的,并且可以为其他启发式算法的最优解提供基准。
为了加速组合搜索,我们首先观察到通常一些点与任何其他点的距离不超过r(即上面找到的图并未表示v的所有点)。我们可以将这些点放在一边,因为它们必然是v1的一部分,但不会干扰搜索的其余部分(下面称之为“单例”)。其次,如果它们不完全不相交,我们会削减无望的“线索”(组合扩展中的前缀)。这通过切断整个搜索空间的大片区域来显著加速完整搜索。如果没有削减前缀,则完整搜索的时间呈指数增长。
这个的速度是多少?它取决于v向量的分布,以及与距离r(强烈)相关。实际上,它取决于找到的聚类数。为了给出一个想法,在2D中均匀选择v 20个向量,我观察到大约30毫秒。对于40个向量,通常在100毫秒左右,但对于某些r值,它可能会跳到超过2秒。
我们实现了combinations的变体,它具有一个check函数来削减不太有希望的前缀:
from itertools import combinations
def _okall(tup, *args, **kwargs):
return True
def combinations_all(iterable, n0=1, n1=None, check=None, *args, **kwargs):
pool = tuple(iterable)
n = len(pool)
if n0 > n:
return
n1 = n if n1 is None else n1
check = _okall if check is None else check
if n0 < 1:
yield ()
n0 = 1
seed = list(combinations(range(n), n0-1))
for r in range(n0, n1+1):
prev_seed = seed
seed = []
for prefix in prev_seed:
for j in range(max(prefix, default=-1)+1, n):
indices = prefix + (j,)
tup = tuple(pool[i] for i in indices)
if check(tup, *args, **kwargs):
seed.append(indices)
yield tup
例子:
>>> list(combinations_all(range(4), check=lambda tup: tup[:2] != (0,1)))
[(0,),
(1,),
(2,),
(3,),
(0, 2),
(0, 3),
(1, 2),
(1, 3),
(2, 3),
(0, 2, 3),
(1, 2, 3)]
现在,我们使用它来查找最小不相交覆盖并返回
v1的索引:
def check(tup, graph):
if len(tup) < 2:
return True
reach_of_last = graph[tup[-1]]
prefix = set(tup[:-1])
return prefix.isdisjoint(reach_of_last)
def brute_vq(v, r):
n = v.shape[0]
graph = get_graph(v, r)
to_part = set(graph)
singletons = set(range(n)).difference(to_part)
if not to_part:
return sorted(singletons)
for tup in combinations_all(to_part, check=check, graph=graph):
cover = {j for i in tup for j in graph[i]}
if cover == to_part:
v1_idx = sorted(singletons.union(tup))
return v1_idx
示例:
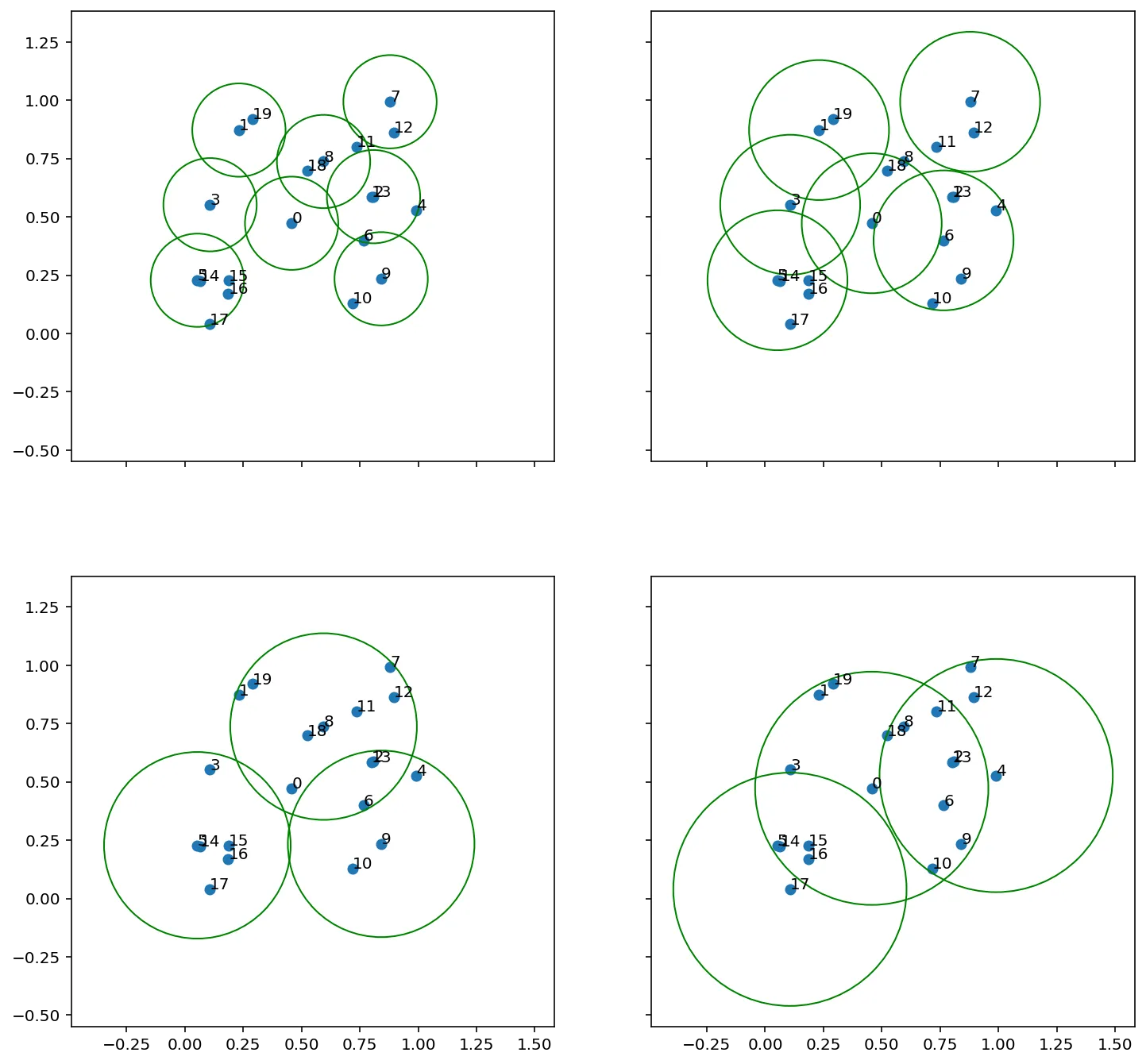
v = np.random.uniform(size=(20, 2))
r_s = [[0.2, 0.3], [0.4, 0.5]]
fig, axes = plt.subplots(nrows=len(r_s), ncols=len(r_s[0]),
figsize=(12,12), sharex=True, sharey=True)
for r, ax in zip(np.ravel(r_s), np.ravel(axes)):
idx = brute_vq(v, r)
ax.set_aspect('equal')
ax.scatter(v[:, 0], v[:, 1])
for i, p in enumerate(v):
ax.text(*p, str(i))
for i in idx:
circ = plt.Circle(v[i], radius=r, color='g', fill=False)
ax.add_patch(circ)
plt.show();
v1成为一组新向量(不一定是v的成员)。我所知道的一个例外是k-medoids。但这并不完全符合您的问题,只是探索的一个领域。其他感兴趣的领域包括分层聚类。 - Pierre D