我正在实现一个音频通道混合器,并使用 Viktor T. Toth's algorithm。尝试混合两个音频通道流。
在代码中,quantization_是通道位深度的字节表示。我的
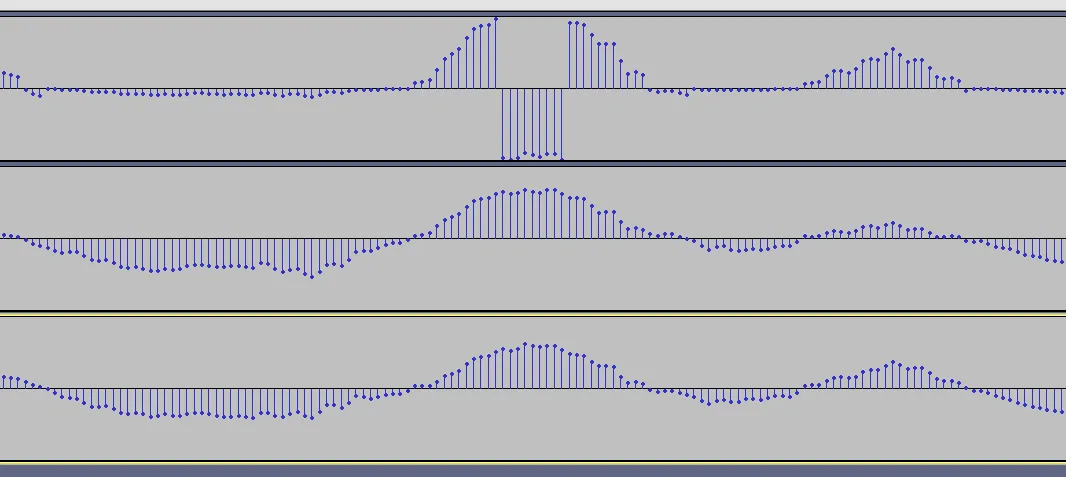
一般来说,它会给出预期的输出样本值。然而,当我在 Audacity中查看输出时,有些样本的值接近于0,这不应该是这样的。在截图中,底部的两个信号是两个单声道,顶部的信号是混合后的信号。可以看到,特别是在中间,有一些非常低的值。
在代码中,quantization_是通道位深度的字节表示。我的
mix函数接受指向目标和源uint8_t缓冲区的指针,将两个通道混合并写入目标缓冲区。因为我正在使用uint8_t缓冲区中的数据,所以需要进行加法、除法和乘法运算来获取实际的8、16或24位样本,并再次将它们转换为8位。一般来说,它会给出预期的输出样本值。然而,当我在 Audacity中查看输出时,有些样本的值接近于0,这不应该是这样的。在截图中,底部的两个信号是两个单声道,顶部的信号是混合后的信号。可以看到,特别是在中间,有一些非常低的值。
mix 函数;void audio_mixer::mix(uint8_t* dest, const uint8_t* source)
{
uint64_t mixed_sample = 0;
uint64_t dest_sample = 0;
uint64_t source_sample = 0;
uint64_t factor = 0;
for (int i = 0; i < channel_size_; ++i)
{
dest_sample = 0;
source_sample = 0;
factor = 1;
for (int j = 0; j < quantization_; ++j)
{
dest_sample += factor * static_cast<uint64_t>(*dest++);
source_sample += factor * static_cast<uint64_t>(*source++);
factor = factor * 256;
}
mixed_sample = (dest_sample + source_sample) - (dest_sample * source_sample / factor);
dest -= quantization_;
for (int k = 0; k < quantization_; ++k)
{
*dest++ = static_cast<uint8_t>(mixed_sample % 256);
mixed_sample = mixed_sample / 256;
}
}
}