我正在尝试学习 purrr,使用 rnorm 模拟具有不同均值、标准差和每次迭代中不同数量的数据。这段代码生成了我的数据框:
现在我想迭代不同的模拟,对于每一行,使用rnorm按照均值、标准差和r生成数据。
这是我的数据框的样子: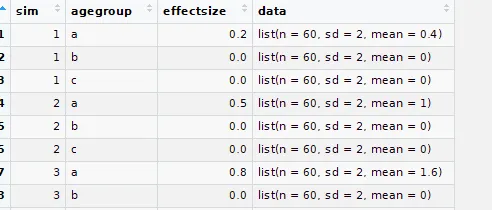
现在我想要创建均值、标准差和 n 在“data”列中给出的正态分布数据。
然而,上述代码会出现一个错误,我还没有找到解决方法:
我读了《R数据科学》中的迭代章节并进行了一些谷歌搜索,但我无法弄清楚如何将pmap和nest结合起来使用。我之所以想使用这些函数是因为它们可以更容易地将参数、模拟数据和输出全部放在一个数据框中。
parameter = crossing(n = c(60,80,100),
agegroup = c("a", "b","c"),
effectsize = c(0.2, 0.5, 0.8),
sd =2
) %>%
# create a simulation id number
group_by(agegroup) %>%
mutate(sim= row_number())%>%
ungroup() %>%
mutate(# change effect size so that one group has effect, others d=0
effectsize= if_else(agegroup == "a", effectsize, 0),
# calculate the mean for the distribution from effect size
mean =effectsize*sd)
现在我想迭代不同的模拟,对于每一行,使用rnorm按照均值、标准差和r生成数据。
# create a nested dataframe to iterate over each simulation and agegroup
nested_df = parameter %>%
group_by(sim, agegroup, effectsize)%>%
nest() %>% arrange(sim)
这是我的数据框的样子:
现在我想要创建均值、标准差和 n 在“data”列中给出的正态分布数据。
nested_df = nested_df %>%
mutate(data_points = pmap(data,rnorm))
然而,上述代码会出现一个错误,我还没有找到解决方法:
Error in mutate_impl(.data, dots) :
Evaluation error: unused arguments
我读了《R数据科学》中的迭代章节并进行了一些谷歌搜索,但我无法弄清楚如何将pmap和nest结合起来使用。我之所以想使用这些函数是因为它们可以更容易地将参数、模拟数据和输出全部放在一个数据框中。