我有一个圆形增长算法(具有闭合链接的线性增长),每次迭代都会在现有点之间添加新点。
每个点的关联信息存储在列表中的元组中。该列表进行迭代更新。
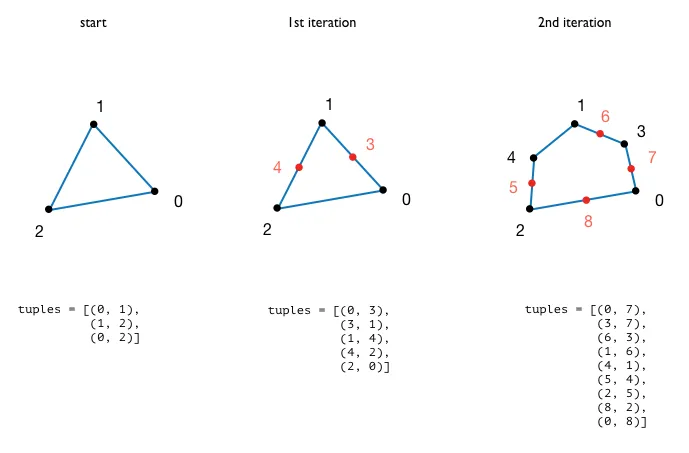
问题:
以列表形式返回这些点的空间顺序,最有效的方法是什么?
我是否需要在每次迭代时计算整个顺序,还是有一种方式可以按顺序将新点累加地插入到该列表中?
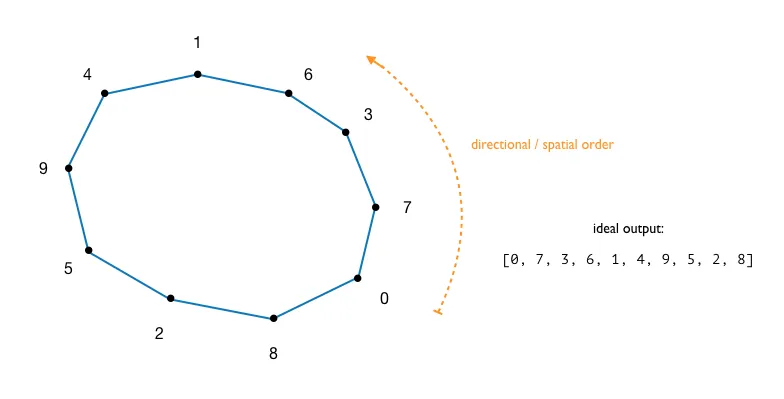
我能想到的唯一方法如下:
tuples = [(1, 4), (2, 5), (3, 6), (1, 6), (0, 7), (3, 7), (0, 8), (2, 8), (5, 9), (4, 9)]
starting_tuple = [e for e in tuples if e[0] == 0 or e[1] == 0][0]
## note: 'starting_tuple' could be either (0, 7) or (0, 8), starting direction doesn't matter
order = list(starting_tuple) if starting_tuple[0] == 0 else [starting_tuple[1], starting_tuple[0]]
## order will always start from point 0
idx = tuples.index(starting_tuple)
## index of the starting tuple
def findNext():
global idx
for i, e in enumerate(tuples):
if order[-1] in e and i != idx:
ind = e.index(order[-1])
c = 0 if ind == 1 else 1
order.append(e[c])
idx = tuples.index(e)
for i in range(len(tuples)/2):
findNext()
print order
它可以工作,但既不优雅(非Pythonic),也不高效。 我认为递归算法可能更合适,但不幸的是我不知道如何实现这样的解决方案。
另外,请注意我正在使用Python 2,并且只能访问完整的Python包(没有numpy)。
order = [starting_tuple[0], starting_tuple[1]]替换为order = list(starting_tuple)。 - Jab(7, 0)或(8, 0)之一,那会怎样?这种情况可能发生吗?它会不会破坏你最初的假设? - cdlane