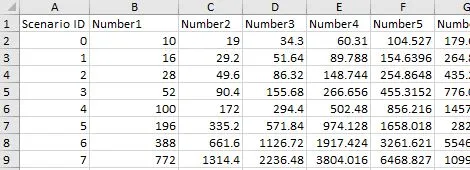
我想将数据集从这样的形式转换为非标准化形式:
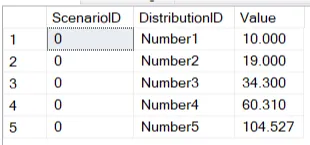
转换后的数据如下所示:
+-------------+-----------------+---------+
| Scenario ID | Distribution ID | Value |
+-------------+-----------------+---------+
| 0 | Number1 | 10 |
| 0 | Number2 | 19 |
| 0 | Number3 | 34.3 |
| 0 | Number4 | 60.31 |
| 0 | Number5 | 104.527 |
+-------------+-----------------+---------+
使用SQL系统管理工作室。
我认为我应该使用基于类似这样的代码:
SELECT *
FROM
(
SELECT 1
FROM table_name
) AS cp
UNPIVOT
(
Scenario FOR Scenarios IN (*
) AS up;
有谁能帮助我吗?我不知道如何编码,刚开始学习。提前感谢!