我希望在日志行中添加特定URI参数的字段
以下是一个示例日志行:
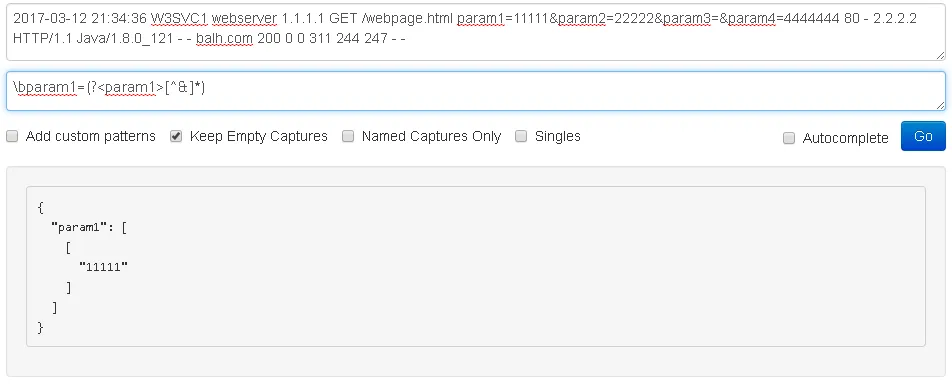
2017-03-12 21:34:36 W3SVC1 webserver 1.1.1.1 GET /webpage.html param1=11111¶m2=22222¶m3=¶m4=4444444 80 - 2.2.2.2 HTTP/1.1 Java/1.8.0_121 - - balh.com 200 0 0 311 244 247 - -
我希望增加param1,param2,param3和param4字段。
我正在使用以下grok过滤器:
grok {
match => [ "message", "(?<param1>param1=(.*?)&)"]
}
所以这个正则表达式使用捕获组来获取在“param1=”和“&”之间的文本。但是grok忽略了捕获组,得到了“param1=11111&”。我只想捕获“111111”。
我该如何使用捕获组1或告诉grok使用我的正则表达式捕获组?
编辑 这个几乎可以工作:
grok {
match => [ "message", "(?<param1>param1=(?<param1>.*?)&)"]
}
我猜我在这里使用了两个同名的命名组。问题在于“param1”字段对于每个组都有两个条目。“param1=11111&”和“11111”各有一个。我怎样才能只获取第二个组呢?