我们需要决定在一些文本处理项目中,是选用支持向量机还是快速人工神经网络。该项目包括上下文拼写纠正以及将文本标记为某些短语及其同义词。哪种方法更合适?或者是否有比FANN和SVM更适宜的替代方案?
文本处理应使用支持向量机还是人工神经网络?
14
- Arc
1
2我正在投票关闭此问题,因为它不属于[帮助中心]定义的编程范畴,而是关于机器学习理论和/或方法论的。 - desertnaut
4个回答
14
我认为你可以从这两个算法中得到有竞争力的结果,因此你应该汇总这些结果......考虑集成学习。
更新:
我不知道是否具体到足够程度:使用贝叶斯最优分类器来结合每个算法的预测。您必须训练这两种算法,然后训练贝叶斯最优分类器来使用它们并根据算法输入作出最优预测。
把你的训练数据分为三部分:
- 第一个数据集将用于训练(人工)神经网络和支持向量机。
- 第二个数据集将用于通过从ANN和SVM中获取原始预测来训练贝叶斯最优分类器。
- 第三个数据集将是您的资格数据集,在其中测试您训练的贝叶斯最优分类器。
更新2.0:
创建算法集成的另一种方法是使用10倍(或更普遍地,k倍)交叉验证:
- 将数据分为大小为n/10的10个集合。
- 在9个数据集上进行训练并在1个数据集上进行测试。
- 重复10次,取平均准确率。
请记住,通常可以结合多种分类器和验证方法以产生更好的结果。这只是找到最适合您领域的方法的问题。
- Kiril
2
你能再帮我详细说明一下需要使用哪些东西吗? - Arc
@Akrid 我已经更新了我的评论...这有帮助吗?还是你需要更多的信息? - Kiril
8
您可能还想看看maxent分类器(/对数线性模型)。它们在自然语言处理问题中非常流行。现代实现使用拟牛顿方法进行优化,而不是较慢的迭代缩放算法,训练速度比支持向量机更快。它们似乎也对正则化超参数的精确值更不敏感。如果您想免费获得特征组合,则应该仅首选SVM而不是maxent。
至于SVM与神经网络的比较,使用SVM可能比使用ANN更好。像maxent模型一样,训练SVM是一个凸优化问题。这意味着,在给定数据集和特定分类器配置的情况下,SVM将始终找到相同的解决方案。当训练多层神经网络时,系统可能会收敛到各种局部最小值。因此,您将根据用于初始化模型的权重获得更好或更差的解决方案。使用ANN,您需要执行多个训练运行以评估给定模型配置的好坏。
- dmcer
1
1虽然我很喜欢Hal的博客,但在MS Paint中制作的图并不能证明逻辑回归比SVM对超参数选择不太敏感。不过除此之外,这是一个非常好的回答。 - Stompchicken
2
这是一道很老的问题。在过去的7年里,自然语言处理领域发生了很多进展。
在此期间,卷积神经网络和循环神经网络得到了发展。 词向量:出现在相似上下文中的单词具有类似的含义。词向量是在一个任务上进行预训练的,该任务的目标是根据其上下文预测一个单词。
RNN是专门处理序列信息的神经网络方法。
RNN会记忆先前计算的结果,并在当前计算中使用它。
请查看以下资源: 深度学习在自然语言处理中的应用 深度学习的最新趋势论文
在此期间,卷积神经网络和循环神经网络得到了发展。 词向量:出现在相似上下文中的单词具有类似的含义。词向量是在一个任务上进行预训练的,该任务的目标是根据其上下文预测一个单词。
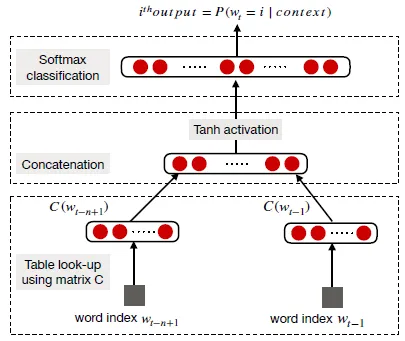
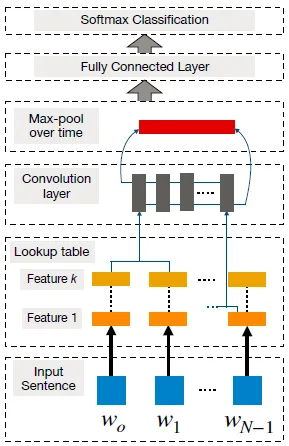
首先将句子分词成单词,并将其转换为一个维度为d的单词嵌入矩阵(即输入嵌入层)。
在该输入嵌入层上应用卷积滤波器以生成特征图。
对于每个滤波器,进行最大池化操作以获得固定长度的输出并降低输出的维度。
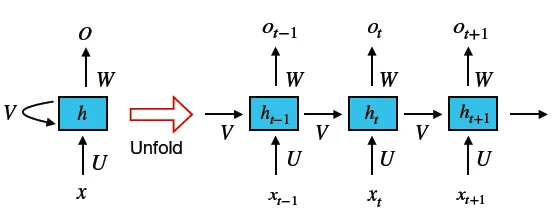
RNN是专门处理序列信息的神经网络方法。
RNN会记忆先前计算的结果,并在当前计算中使用它。
请查看以下资源: 深度学习在自然语言处理中的应用 深度学习的最新趋势论文
- Ravindra babu
-1
您可以使用卷积神经网络(CNN)或循环神经网络(RNN)来训练自然语言处理(NLP)。我认为现在CNN已经达到了最先进的水平。
- Minh Phan
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接