对于那些试图将
SNR与由numpy生成的正常随机变量联系起来的人们:
[1]

,这里需要牢记P是平均功率。
或者用dB表示:
[2]

在这种情况下,我们已经有一个信号,我们想生成噪声以给我们所需的SNR。
噪声的
类型因所建模型而异,但对于这个射电望远镜的例子来说,一个很好的起点是
加性白高斯噪声(AWGN)。如前面的回答所述,要建模 AWGN,需要将一个零均值高斯随机变量添加到原始信号中。该随机变量的方差将影响
平均噪声功率。
对于高斯随机变量 X,平均功率

,也称为第
二矩, 是
[3]

因此,对于白噪声,

,平均功率等于方差

。
当在Python中对此进行建模时,您可以选择:
1. 根据所需的SNR和一组现有测量值计算方差。如果您希望测量具有相当一致的幅度值,则此方法适用。
2. 或者,您可以将噪声功率设置为已知水平,以匹配接收器噪声之类的内容。可以通过将望远镜对准自由空间并计算平均功率来测量接收器噪声。
无论哪种方式,重要的是要确保向信号添加噪声,并在线性空间而不是dB单位中进行平均。
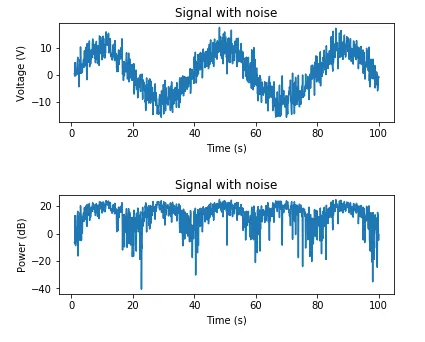
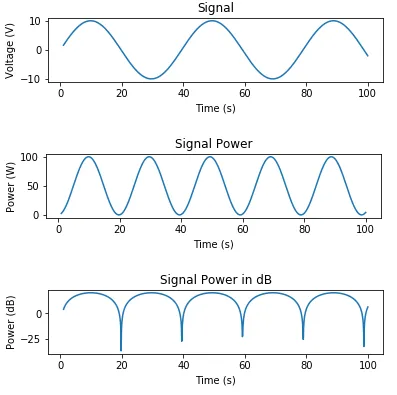
以下是一些生成信号并绘制电压、瓦特数和分贝功率的代码:
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(1, 100, 1000)
x_volts = 10*np.sin(t/(2*np.pi))
plt.subplot(3,1,1)
plt.plot(t, x_volts)
plt.title('Signal')
plt.ylabel('Voltage (V)')
plt.xlabel('Time (s)')
plt.show()
x_watts = x_volts ** 2
plt.subplot(3,1,2)
plt.plot(t, x_watts)
plt.title('Signal Power')
plt.ylabel('Power (W)')
plt.xlabel('Time (s)')
plt.show()
x_db = 10 * np.log10(x_watts)
plt.subplot(3,1,3)
plt.plot(t, x_db)
plt.title('Signal Power in dB')
plt.ylabel('Power (dB)')
plt.xlabel('Time (s)')
plt.show()
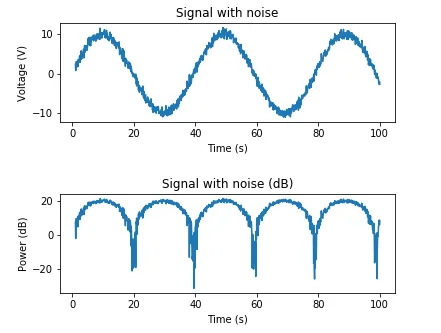
这是一个根据期望信噪比添加AWGN的示例:
target_snr_db = 20
sig_avg_watts = np.mean(x_watts)
sig_avg_db = 10 * np.log10(sig_avg_watts)
noise_avg_db = sig_avg_db - target_snr_db
noise_avg_watts = 10 ** (noise_avg_db / 10)
mean_noise = 0
noise_volts = np.random.normal(mean_noise, np.sqrt(noise_avg_watts), len(x_watts))
y_volts = x_volts + noise_volts
plt.subplot(2,1,1)
plt.plot(t, y_volts)
plt.title('Signal with noise')
plt.ylabel('Voltage (V)')
plt.xlabel('Time (s)')
plt.show()
y_watts = y_volts ** 2
y_db = 10 * np.log10(y_watts)
plt.subplot(2,1,2)
plt.plot(t, 10* np.log10(y_volts**2))
plt.title('Signal with noise (dB)')
plt.ylabel('Power (dB)')
plt.xlabel('Time (s)')
plt.show()
下面是一个根据已知噪声功率添加AWGN的示例:
target_noise_db = 10
target_noise_watts = 10 ** (target_noise_db / 10)
mean_noise = 0
noise_volts = np.random.normal(mean_noise, np.sqrt(target_noise_watts), len(x_watts))
y_volts = x_volts + noise_volts
plt.subplot(2,1,1)
plt.plot(t, y_volts)
plt.title('Signal with noise')
plt.ylabel('Voltage (V)')
plt.xlabel('Time (s)')
plt.show()
y_watts = y_volts ** 2
y_db = 10 * np.log10(y_watts)
plt.subplot(2,1,2)
plt.plot(t, 10* np.log10(y_volts**2))
plt.title('Signal with noise')
plt.ylabel('Power (dB)')
plt.xlabel('Time (s)')
plt.show()