如果我说错了什么,请纠正我。
你的问题有一个带有"未定义行为"的标志。我认为这是不正确的。
如果你对程序有任何疑问,我建议查看程序的反汇编代码。通过检查它,你所有的困惑可能会很容易地解决。
输出:
-2 254
-2 254
这是正确的,这是一种确定的行为。这种行为是由C语言本身或C语言标准决定的。
输出的关键取决于程序员如何解释存储的值
FE。如果将
FF视为无符号字符,则为
255(或将
FFFF视为无符号短整型,则为
65535,或将
FFFFFFFF视为无符号整型,则为
4294967295)。如果将
FF视为有符号字符,则为
-1(或将
FFFF视为有符号短整型,则为
-1,或将
FFFFFFFF视为有符号整型,则为
-1)。
同样,如果将
FE视为无符号字符,则为
254。如果将
FE视为有符号字符,则为
-2。依此类推......
当你要求计算机存储"-2"和"254"时,计算机并不识别正数或负数,它只识别"0"(在电路中,可以说是"断开"或"损坏")和"1"(在电路中,可以说是"闭合"或"连接")。如果你要求计算机存储"-2",它会在内存中的某个位置存储"FE"(因为变量c和变量d的类型是char,占用1个字节)。正如@David C. Rankin指出的,在将负数编码为二进制补码的计算机上。同样地,如果你要求计算机存储"254",它也会在内存中的某个位置存储"FE"。
请参考下面的代码:
#include <stdio.h>
int main()
{
signed char c;
unsigned char d;
c = (signed char) 0xFE;
d = (unsigned char) c;
printf("%d %d\n", c, d);
d = (unsigned char)0xFE;
c = (signed char) d;
printf("%d %d\n", c, d);
return 0;
}
使用以下命令运行它:
clang -Wall -Wextra -pedantic -std=c89 foo.c && ./a.out
将输出:
-2 254
-2 254
为什么输出是双数“-2 254”?
代码中没有出现“-2”和“254”。
似乎只观察到了数字“0xFF”。
c = (signed char) 0xFE;
d = (unsigned char)0xFE;
那么,-2和254是从哪里来的?
简单解释:(下面有更详细的解释)

我们发现
变量c和
变量d是
char类型,但
%d输出的是
int(或有符号整数),编译器应该如何处理?答案是
有符号扩展和无符号扩展。
所以现在存储在
变量c中的值
0xFE通过符号扩展转换为
0xFFFFFFFE,而存储在
变量d中的值
0xFE通过零扩展转换为
0x000000FE。当使用
%d打印
0xFFFFFFFE时,输出结果为
-2,而使用
%d打印
0x000000FE时,输出结果为
254。(对于
0xFFFFFFFE你可能不太熟悉或不太理解吗?请继续阅读,下面有解释。)
或者像下面这样的代码:
#include <stdio.h>
int main()
{
signed char c;
unsigned char d;
c = (signed char) 254;
d = (unsigned char) c;
printf("%d %d\n", c, d);
d = (unsigned char)254;
c = (signed char) d;
printf("%d %d\n", c, d);
return 0;
}
使用以下命令运行它:
clang -Wall -Wextra -pedantic -std=c89 foo.c && ./a.out
将输出:
-2 254
-2 254
为了更好地解释您的困惑,请看一下以下代码。
#include <stdio.h>
int main()
{
signed char c;
unsigned char d;
c = (signed char) -2;
d = (unsigned char) c;
printf("%d %d %u %u\n", c, d, c, d);
d = (unsigned char) 254;
c = (signed char) d;
printf("%d %d %u %u\n", c, d, c, d);
return 0;
}
使用以下命令运行它:
clang -Wall -Wextra -pedantic -std=c89 foo.c && ./a.out
将输出:
-2 254 4294967294 254
-2 254 4294967294 254
或者使用以下命令运行它:
gcc -g -o foo foo.c && ./foo
将输出:
-2 254 4294967294 254
-2 254 4294967294 254
输出是正确的。
更多详细解释:

我们发现变量c或变量d是char类型,但是%u输出的是unsigned int类型,编译器应该如何处理?答案是进行有符号扩展和无符号扩展。
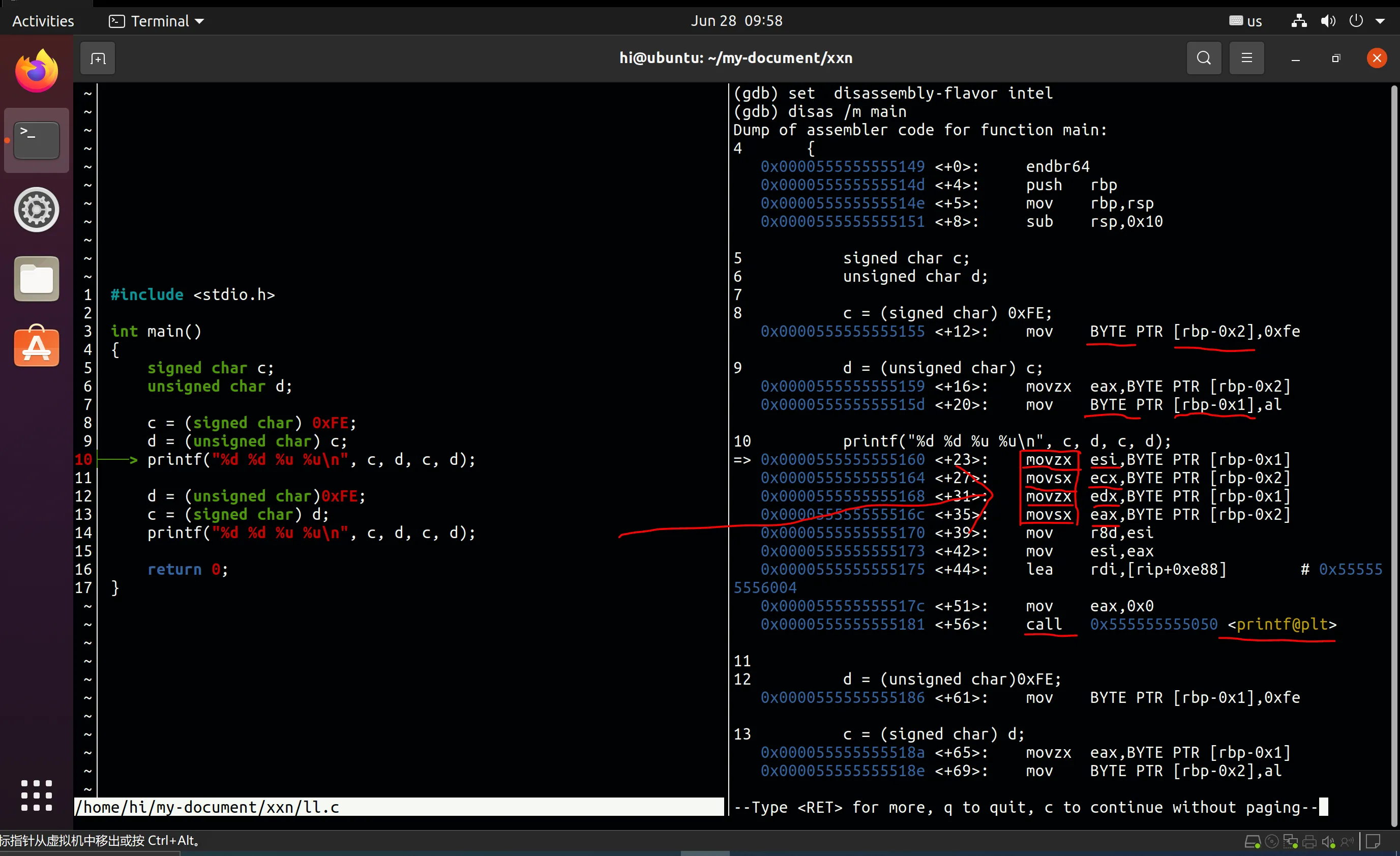
当我们检查反汇编代码时,确实发现了符号扩展和零扩展。请参考下面的图片。
另一张图片:
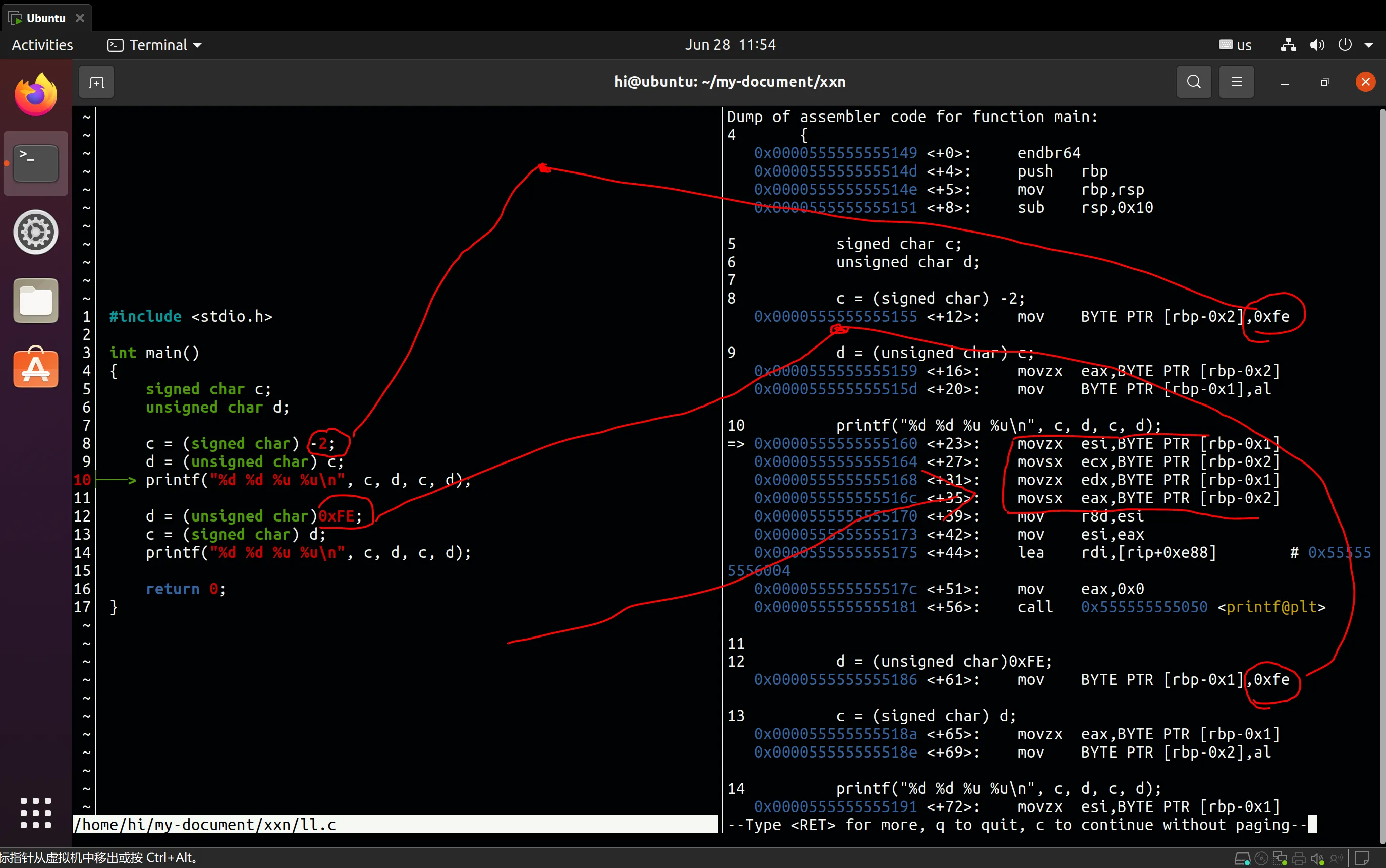
我们发现在给变量c和变量d赋值时使用了char类型(BYTE),但在printf之前,变量c和变量d的值
之前有一些指令。
movzx esi,BYTE PTR [rbp-0x1]
movsx ecx,BYTE PTR [rbp-0x2]
movzx edx,BYTE PTR [rbp-0x1]
movsx eax,BYTE PTR [rbp-0x2]
movzx是零扩展,而movsx是符号扩展。就像esi、ecx、edx、eax等于int(ecx占据4个字节,int类型也占据4个字节)。
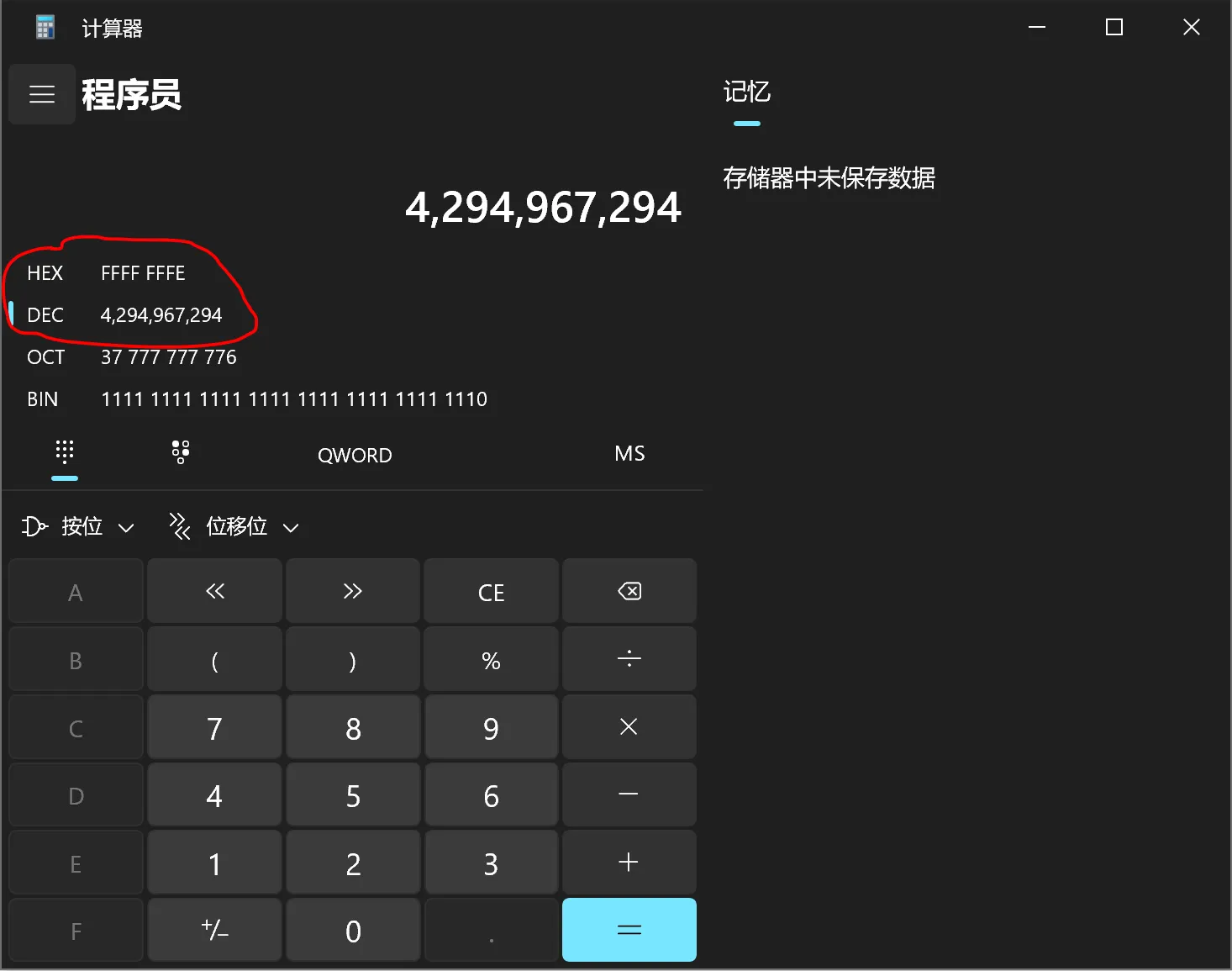
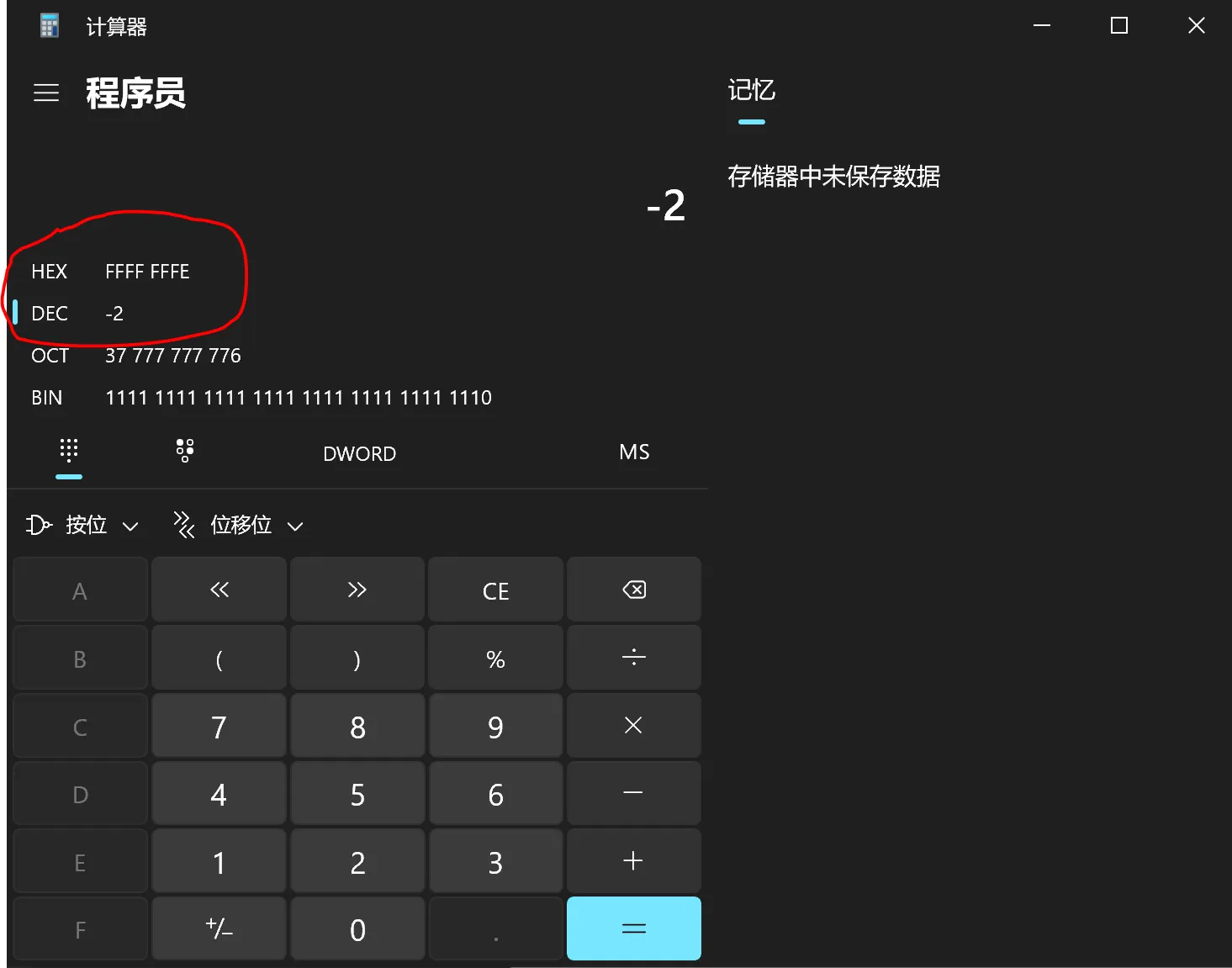
所以现在存储在变量c中的值0xFE通过符号扩展被转换为0xFFFFFFFE(保存在ecx或eax中),而存储在变量d中的值0xFE通过零扩展被转换为0x000000FE(保存在esi或edx中)。当使用%u打印0xFFFFFFFE时,结果为4294967294;当使用%d打印0xFFFFFFFE时,结果为-2;当使用%u打印0x000000FE时,结果为254;当使用%d打印0x000000FE时,结果为254。
4294967294的表示如下图所示。
-2的表示如下图所示。
所以现在你看到,当输出
变量c或
变量d的值时,使用%d和%u来打印它们会得到不同的结果。然而,这两种表示都指向存储在内存中的同一个值。
关键是你选择如何解释c或d的值。
unsigned值在signed的正数范围内时,才能明确定义。因此,如果char是8位,那么只有当值介于0和127之间时,才能明确定义。 - Barmarprintf在UCHAR_MAX > INT_MAX的系统上可能会有问题,尽管这是另一个完全不同的帖子。 - M.Mprintf在 UCHAR_MAX > INT_MAX 的系统上可能会有问题,尽管这是另一个完全不同的帖子。 - M.Mchar的平台上,即使所有规则都被定义,-2也不会是254。 - phuclvchar的平台上,即使所有规则都被定义,-2也不会是254。 - phuclv