library(data.table)
DATA=data.table(STUDENT= c(1,2,3,4),
DOG_1= c("a","e","a","c"),
DOG_2= c("a","e","d","b"),
DOG_3= c("a","d","b","c"),
CAT_1= c("c","a","d","c"),
CAT_2= c("c","d","a","b"),
MOUSE_1= c("d","b","e","b"),
MOUSE_2= c("c","a","b","e"),
MOUSE_3= c("a","b","b","e"),
MOUSE_4= c("b","c","a","d"))
这是我的数据的样子。我希望得到一个新的数据,它的样子应该像这样:
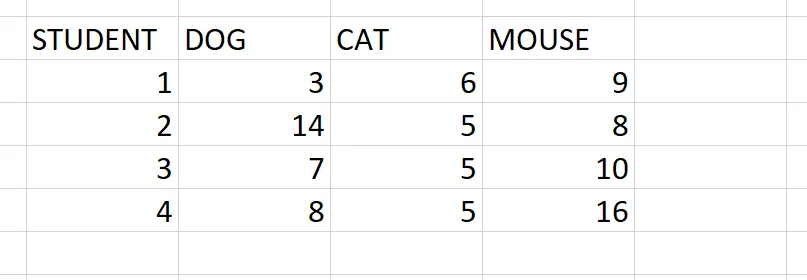
其中'a'等于1;'b'等于2;'c'等于3;'d'等于4;'e'等于5,例如要获取STUDENT 1 DOG的值为3,需要将字母转换为对应的数值并求和。