我正在编写一个Python脚本,在一个大的二进制文件中搜索几个不同的字节字符串,目前为止它运行得很好,但是我遇到了一个小问题。以下是我迄今为止所做的:
for i in range(0, fileSizeBytes):
data.seek(readOffsetIndex, 0) # Change the file index to last search.
print('Starting Read at DEC: %s' % str(readOffsetIndex))
print('Starting Read at HEX: %s' % str(hex(readOffsetIndex)))
byte = data.read() # Read the file starting at the new index
search = byte.find(b'\x00\x00\x00\xbb') # Search for this string of bytes
if search:
byteOffset = (byteOffset + (busWidth+4))
startOffset = str(hex(byteOffset-4))
readOffsetIndex = byteOffset
print('String Found Starting at: ' + startOffset)
print('READ SET TO: %s' % str(readOffsetIndex))
print('READ SET TO: %s' % str(hex(readOffsetIndex)))
print('---------------------------------------------------')
csvWriter.writerow(['Bus Width', str(startOffset), str(hex(readOffsetIndex)), grabData(byteOffset-4)])
if (readOffsetIndex >= fileSizeBytes): # Check bounds of file size to kill loop
csvFile.close()
break
它尝试查找的唯一查询是:search = byte.find(b'\x00\x00\x00\xbb')。当我分析数据时,少数记录是完美的,但当我命中搜索位置0x189da6b时,它就变得很疯狂。请参见下面的图像以获取数据输出:
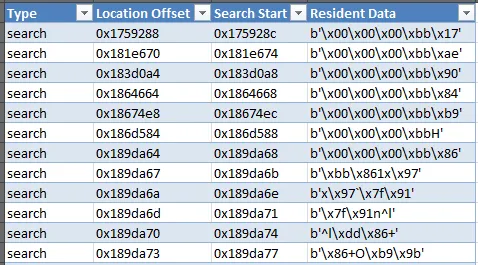
好像它停止寻找特定的字符串并开始做自己的事情...你有什么想法吗?CSV文件共有88,900行,其中约90行是有效的搜索字符串,其余都是您在数据中看到的无意义字符。
更新#1:
我发现了一种更好的方法来迭代二进制文件并定位所有出现的字节字符串以及所述字节字符串的偏移量。下面是一个可以做到这一点的方法:
from bitstring import ConstBitStream
def parse(register_name,byte_data):
fileSizeBytes = os.path.getsize(bin_file)
fileSizeMegaBytes = GetFileSize(os.path.getsize(bin_file))
data = open(bin_file, 'rb')
s = ConstBitStream(filename=bin_file)
occurances = s.findall(byte_data, bytealigned=True)
occurances = list(occurances)
totalOccurances = len(occurances)
byteOffset = 0 # True start of Byte string
for i in range(0, len(occurances)):
occuranceOffset = (hex(int(occurances[i]/8)))
s0f0, length, bitdepth, height, width = s.readlist('hex:16, uint:16, uint:8, 2*uint:16')
s.bitpos = occurances[i]
data = s.read('hex:32')
print('Address: ' + str(occuranceOffset) + ' Data: ' + str(data))
csvWriter.writerow([register_name, str(occuranceOffset), str(data)])