我正在基于最近发布的tensorflow对象检测API建立对象检测管道。 我使用arXiv作为指南。 我希望了解以下内容,以便在自己的数据集上进行训练。
他们是如何选择学习率计划的并且这将如何根据可供训练的GPU数量而改变尚不清楚。 如何根据可用于训练的GPU数量更改训练速率时间表? 该论文提到使用了9个GPU。 如果我只想使用1个GPU,应该如何更改培训速率?
针对Pascal VOC使用Faster R-CNN的发布示例培训配置文件中的初始学习率= 0.0001。 这比原始的Faster-RCNN论文中发布的低10倍。 这是由于假定可用于训练的GPU数量还是由于其他原因导致的?
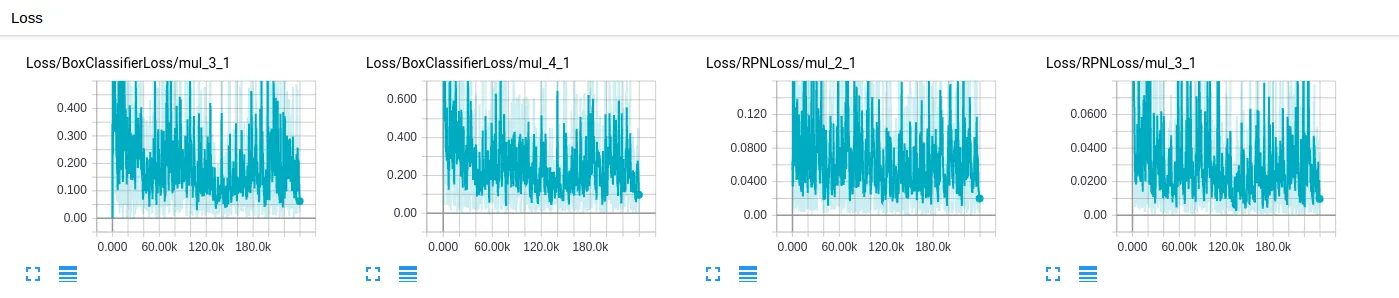
当我从COCO检测检查点开始训练时,培训损失应该如何下降? 查看tensorboard时,使用batch size为1时,我的数据集上的培训损失很低-每次迭代在0.8到1.2之间。 下图显示了来自tensorboard的各种损失情况。 这是预期行为吗?