这个问题是关于C++优化技术的。我有一个大维度的矩阵-向量乘法,想要减少运行时间。我知道有专门的线性代数库,但实际上我想学习一些底层处理器特性。到目前为止,我正在使用\O2(Microsoft)编译,并且我让编译器确认乘法的内部循环已经向量化了。
示例代码如下:
现在我有几个与此相关的问题。
示例代码如下:
#include <stdio.h>
#include <ctime>
#include <iostream>
#define VEC_LENGTH 64
#define ITERATIONS 4000000
void gen_vector_matrix_multiplication(double *vec_result, double *vec_a, double *matrix_B, unsigned int cols_B, unsigned int rows_B)
{
// initialise result vector
for (unsigned int i = 0; i < rows_B; i++)
{
vec_result[i] = 0;
}
// perform multiplication
for (unsigned int j = 0; j < cols_B; j++)
{
const double entry = vec_a[j];
const int col = j*rows_B;
for (unsigned int i = 0; i < rows_B; i++)
{
vec_result[i] += entry * matrix_B[i + col];
}
}
}
int main()
{
double *vec_a = new double[VEC_LENGTH];
double *vec_result = new double[VEC_LENGTH];
double *matrix_B = new double[VEC_LENGTH*VEC_LENGTH];
// start clock
clock_t begin = clock();
// this outer loop is just for test purposes so that the timing becomes meaningful
for (unsigned int i = 0; i < ITERATIONS; i++)
{
gen_vector_matrix_multiplication(vec_result, vec_a, matrix_B, VEC_LENGTH, VEC_LENGTH);
}
// stop clock
double elapsed_time = static_cast<double>(clock() - begin) / CLOCKS_PER_SEC;
std::cout << elapsed_time/(VEC_LENGTH*VEC_LENGTH) << std::endl;
delete[] vec_a;
delete[] vec_result;
delete[] matrix_B;
return 1;
}
为了得到可靠的运行时间估计,需要进行多次乘法。我已经测量了许多不同向量长度的运行时间(在此示例中只有一个元素数量N,它是向量的长度,同时也定义了矩阵的大小NxN),并将测得的运行时间归一化到元素数量。
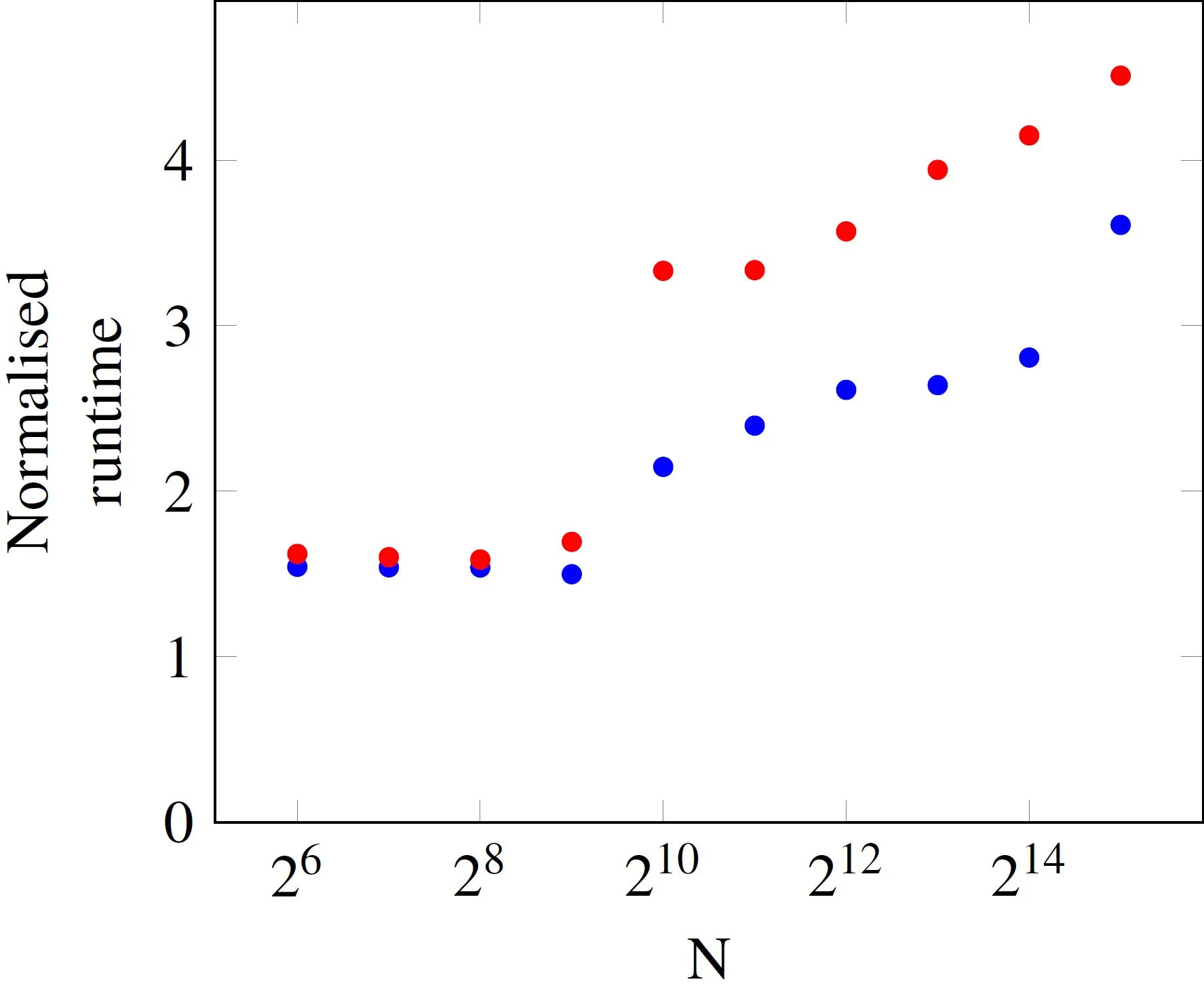
N,每个操作的运行时间是恒定的。然而,在N=512以上,运行时间会增加。蓝色和红色数据点之间的差异是处理器的负载。如果示例程序几乎独自运行,则运行时间由蓝色点给出,当其他核心忙碌时,时间由红色点表示。现在我有几个与此相关的问题。
- 我正确地假设在
N=512和N=1024之间的跳跃与我的处理器(Ivy Bridge i5-3570)的L3缓存大小有关,应该为6MB吗?512*512*8byte大约等于2MB,而1024*1024*8byte大约为8MB。因此,矩阵无法再放入缓存中,从RAM获取数据是执行时间变长的原因? - 超过这个阈值后运行时间稳定增加的原因是什么?
- 你对忙碌和空闲处理器曲线在阈值以上如此不同的原因有何想法?
- 针对
N>1024的操作,优化这个乘法例程的逻辑下一步是什么?
我很想听听您的想法。谢谢!
i + col可能会溢出,使得加载不连续。icc13 可以自动向量化原始代码,但是 gcc 和 clang 只执行标量双精度操作,例如mulsd。这是我进行自动向量化的版本。请注意,它不需要-ffast-math就可以进行向量化,因为矢量*矩阵被卡在了循环多次遍历结果向量或从矩阵进行跨步加载的尴尬位置。虽然可能不值得反转。 - Peter Cordes