我有以下查询。
我得到了一个返回的结果集,看起来像这样:
select * from
(
SELECT distinct
rx.patid
,rx.fillDate
,rx.scriptEndDate
,MAX(datediff(day, rx.filldate, rx.scriptenddate)) AS longestScript
,rx.drugClass
,COUNT(rx.drugName) over(partition by rx.patid,rx.fillDate,rx.drugclass) as distinctFamilies
FROM [I 3 SCI control].dbo.rx
where rx.drugClass in ('h3a','h6h','h4b','h2f','h2s','j7c','h2e')
GROUP BY rx.patid, rx.fillDate, rx.scriptEndDate,rx.drugName,rx.drugClass
) r
order by distinctFamilies desc
这将产生类似于 的结果。
的结果。
这应该意味着在表中的两个日期之间,patID应该有5个独特的药物名称。然而,当我运行以下查询时:
select distinct *
from rx
where patid = 1358801781 and fillDate between '2008-10-17' and '2008-11-16' and drugClass='H4B'
我得到了一个返回的结果集,看起来像这样:
。
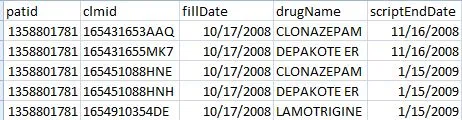
distinctFamilies列。但是,您可以看到,事实上只有三个独特的药品名称。 - wootscootinboogiecount(distinct fieldname1) over(partition by fieldname2)可以解决你的问题。然而,在SQL Server 8中,'count(distinct fieldname)'会报错,所以你需要尝试另一种方法。 - Saju