我有一个像这样的Excel文件:
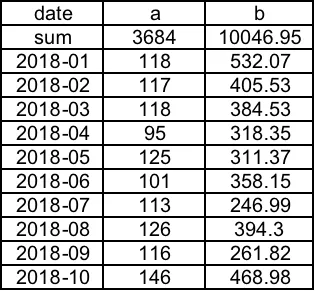
我尝试通过跳过第二行在read.xlsx或read_excel中读取它:
library(xlsx)
df <- read.xlsx('./data.xls', 'Sheet1')
library(readxl)
df <- read_excel("./data.xls", sheet = 'Sheet0', skip = 2, col_names = TRUE)
第一个函数(
read.xlsx)中,我没有找到可以跳过skip行的参数,而第二个函数返回的df没有标题。
请问我在上面的代码中做错了什么,以及如何正确读取?谢谢。
read_csv读取.xlsx文件,当我尝试这样做时,会出现以下错误:第1行似乎包含嵌入的空值,第2行似乎包含嵌入的空值,第3行似乎包含嵌入的空值,第4行似乎包含嵌入的空值,第5行似乎包含嵌入的空值。make.names(col.names, unique = TRUE)中的错误:- ah bon