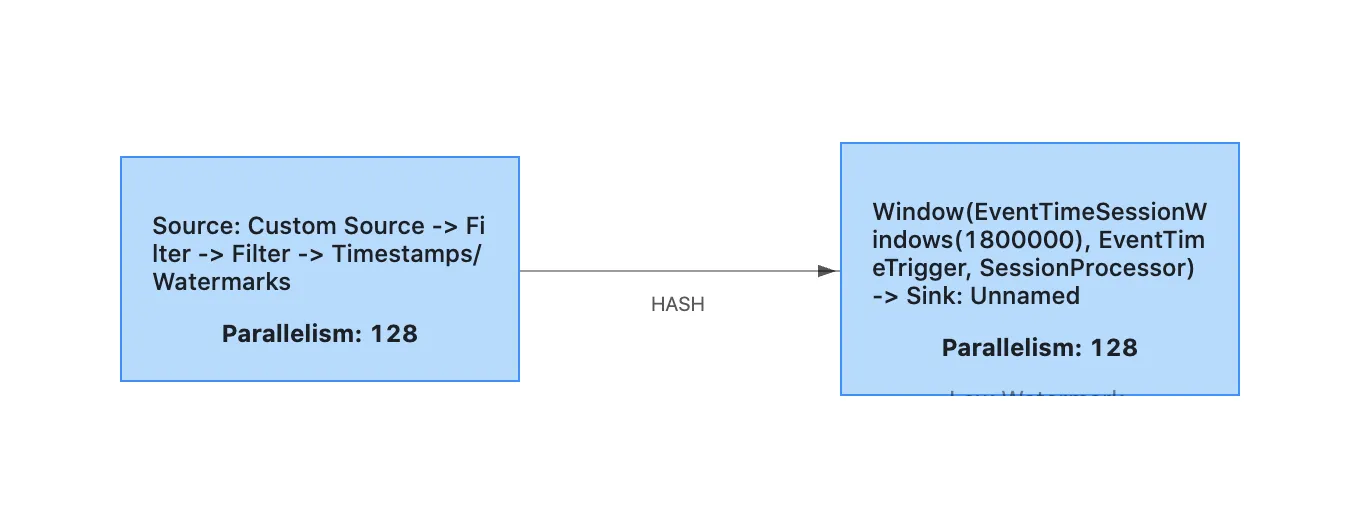
我们正在尝试使用RocksDB后端设置Flink有状态作业。我们使用30分钟的会话窗口,并使用聚合函数,因此不使用任何Flink状态变量。通过采样,我们每秒少于20k个事件,有20-30个新会话/秒。我们的会话基本上收集所有事件。随着时间的推移,会话累加器的大小会增加。我们在Flink 1.9中使用了总共10G内存,128个容器。以下是设置:
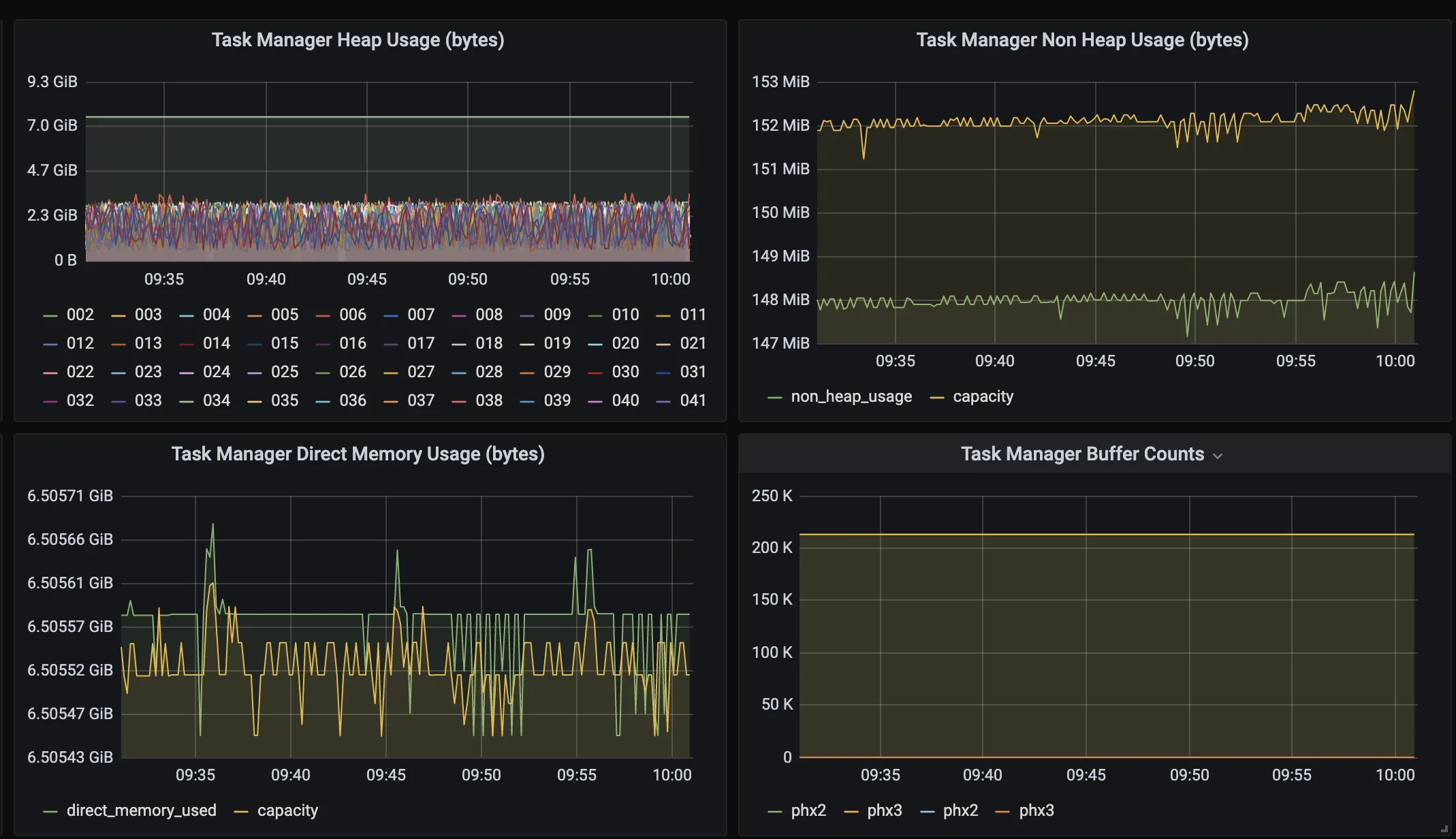
在我们对一段时间的监控中,rocksdb内存表的大小小于10m,我们的堆使用量小于1G,但是我们的直接内存使用量(网络缓冲区)达到了2.5G。缓冲池/缓冲区使用度量都为1(满)。我们的检查点一直失败,我想知道网络缓冲区部分使用这么多内存是否正常?如果您能提出一些建议,我将不胜感激:)谢谢!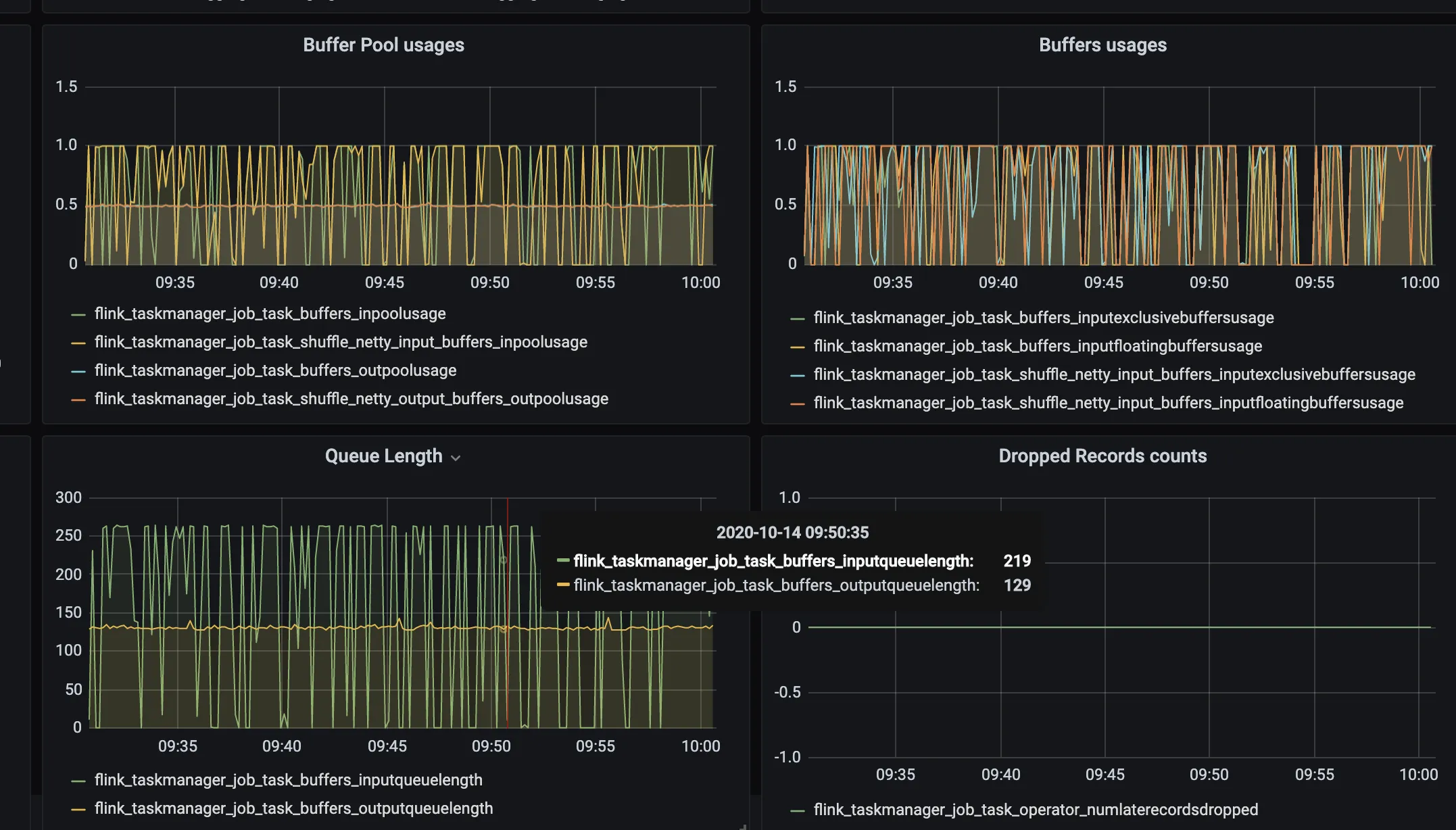
state.backend: rocksdb
state.checkpoints.dir: hdfs://nameservice0/myjob/path
state.backend.rocksdb.memory.managed: true
state.backend.incremental: true
state.backend.rocksdb.memory.write-buffer-ratio: 0.4
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1
containerized.heap-cutoff-ratio: 0.45
taskmanager.network.memory.fraction: 0.5
taskmanager.network.memory.min: 512mb
taskmanager.network.memory.max: 2560mb
在我们对一段时间的监控中,rocksdb内存表的大小小于10m,我们的堆使用量小于1G,但是我们的直接内存使用量(网络缓冲区)达到了2.5G。缓冲池/缓冲区使用度量都为1(满)。我们的检查点一直失败,我想知道网络缓冲区部分使用这么多内存是否正常?如果您能提出一些建议,我将不胜感激:)谢谢!