当我在ddp模式(2个GPU)下启动我的主要脚本时,Pytorch Lightning会复制在主要脚本中执行的所有内容,例如打印或其他逻辑。我需要一些扩展训练逻辑,我希望自己处理。例如,在Trainer.fit()之后执行某些操作(仅一次!)。但是由于主要脚本的复制,这并不按照我想象的方式工作。我也尝试将其包装在if __name__ == "__main__"中,但它并没有改变行为。如何解决这个问题?或者说,如何在不复制主要脚本的情况下使用一些关于我的Trainer对象的逻辑?
Pytorch Lightning在分布式数据并行模式下会复制主脚本。
10
- dlsf
2
1你能提供一些代码吗?由于ddp强制所有节点对模型进行初始化,因此fit中的所有内容都预计会被多次执行,但我假设这不是你的问题?https://pytorch-lightning.readthedocs.io/en/stable/advanced/multi_gpu.html - Fredrik
1谢谢你的回答。是的,这也是我所期望的。然而,似乎不仅 '.fit()' 内部发生了并行计算,而且所有周围的代码也是如此。
例如,当我运行一个脚本 'main.py',在其中按顺序打印一些内容并调用 Trainer.fit() 时,打印的内容会被进程数(GPU 的数量)复制。这显然不是我所期望的。也许有一个解决方法,但与此同时,我发现 PyTorch 中的本地多进程和 ddp 更好(至少对于研究来说),请参见我的答案。 - dlsf
5个回答
8
我现在使用PyTorch中的本地“ddp”和多进程。据我所知,PyTorchLightning(PTL)只是在多个GPU上多次运行主脚本。如果你只想在一次脚本调用中拟合模型,那么这样做是可行的。然而,我认为其中一个巨大的缺点是在训练过程中失去了灵活性。与实验交互的唯一方式是通过这些(文档不好的)回调函数。老实说,使用PyTorch中的本地多进程会更加灵活和方便。最终,它更快且更容易实现,并且您不必在PTL文档中寻找很长时间才能实现简单的事情。
我认为,PTL正在通过消除大量样板代码朝着良好的方向发展,但是,在我的看法中,Trainer概念需要进行一些重大改进。在我看来,它太封闭了,并违反了PTL自己的“重新组织PyTorch代码,保留本机PyTorch代码”的概念。
如果你想要使用PTL进行简单的多GPU训练,我个人强烈建议你不要使用它,对我来说这是浪费时间,最好学习本地的PyTorch多进程。
- dlsf
3
我在 GitHub 仓库上询问了这个问题:https://github.com/PyTorchLightning/pytorch-lightning/issues/8563
有不同的加速器可用于训练,而 DDP(DistributedDataParallel)每个 GPU 运行一次脚本,但 ddp_spawn 和 dp 不会。
然而,某些插件(如 DeepSpeedPlugin)是基于 DDP 构建的,因此更改加速器并不会阻止主要脚本多次运行。
- Viktor Bowallius
2
您可以在Trainer.fit之后添加以下代码来停止重复的子进程:
import sys
if model.global_rank != 0:
sys.exit(0)
其中 model 继承自 LightningModule,后者具有一个属性 global_rank,指定了机器的排名。我们可以大致理解为 gpu id 或进程 id。这段代码之后的所有内容只会在主进程中执行,即 global_rank = 0 的进程。
更多信息,请参考文档 https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_module.html#global_rank
- Laputa
0
从Pytorch Lightning官方DDP文档中,我们知道PL有意多次调用主脚本来启动负责GPU的子进程:
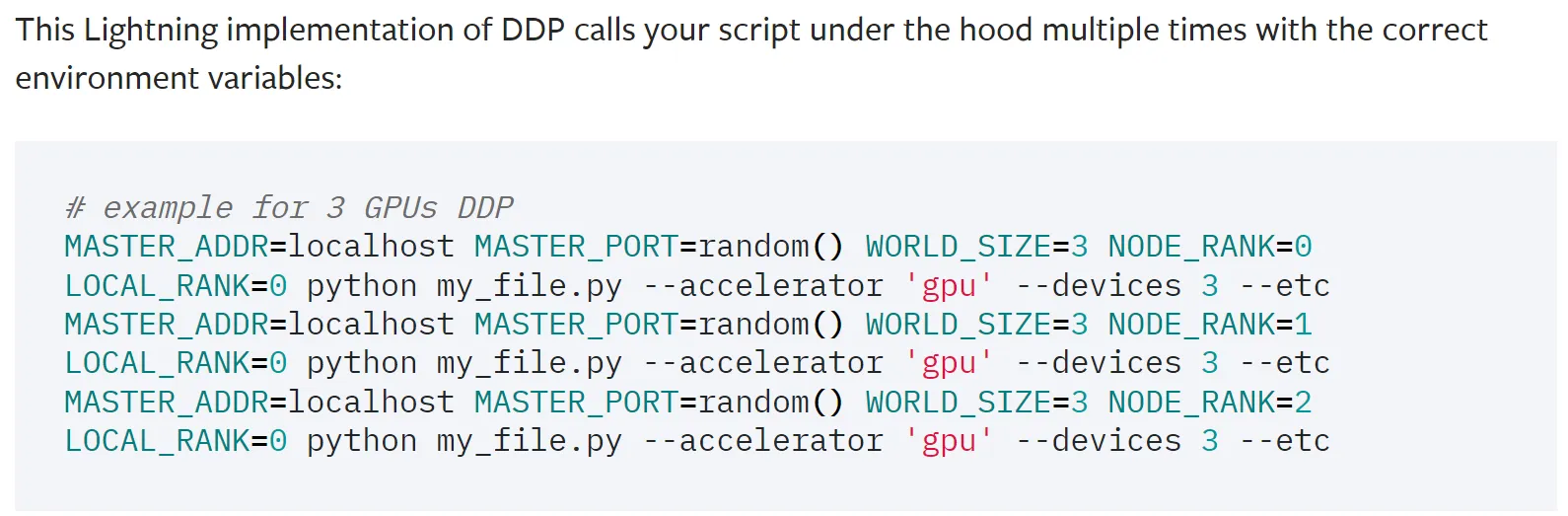
import os
if __name__ == "__main__":
if 'LOCAL_RANK' not in os.environ.keys() and 'NODE_RANK' not in os.environ.keys():
# code you only want to run once
- donets20
0
使用全局变量:
if __name__ == "__main__":
is_primary = os.environ.get(IS_PTL_PRIMARY) is None
os.environ[IS_PTL_PRIMARY] = "yes"
## code to run on each GPU
if is_primary:
## code to run only once
- dkatsios
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 Pytorch Lightning 推理
- 5 加载 PyTorch Lightning 训练的检查点。
- 9 Pytorch Lightning 模型的输出预测
- 5 从 PyTorch lightning 模型中检索 PyTorch 模型
- 6 在PyTorch中使用分布式数据并行(DDP)进行训练时,正确的检查点方式是什么?
- 8 PyTorch Lightning 训练控制台输出异常。
- 48 PyTorch的并行方法和分布式方法是如何工作的?
- 9 PyTorch - 分布式数据并行学习中如何保存和加载模型
- 3 如何在PyTorch中正确使用分布式数据并行?
- 3 validation_epoch_end在DDP Pytorch Lightning中的应用