我正在尝试使用ARIMA模型进行预测,但我对此还很陌生。我尝试绘制我的数据集(每小时数据)的季节性分解图,以下是该图:
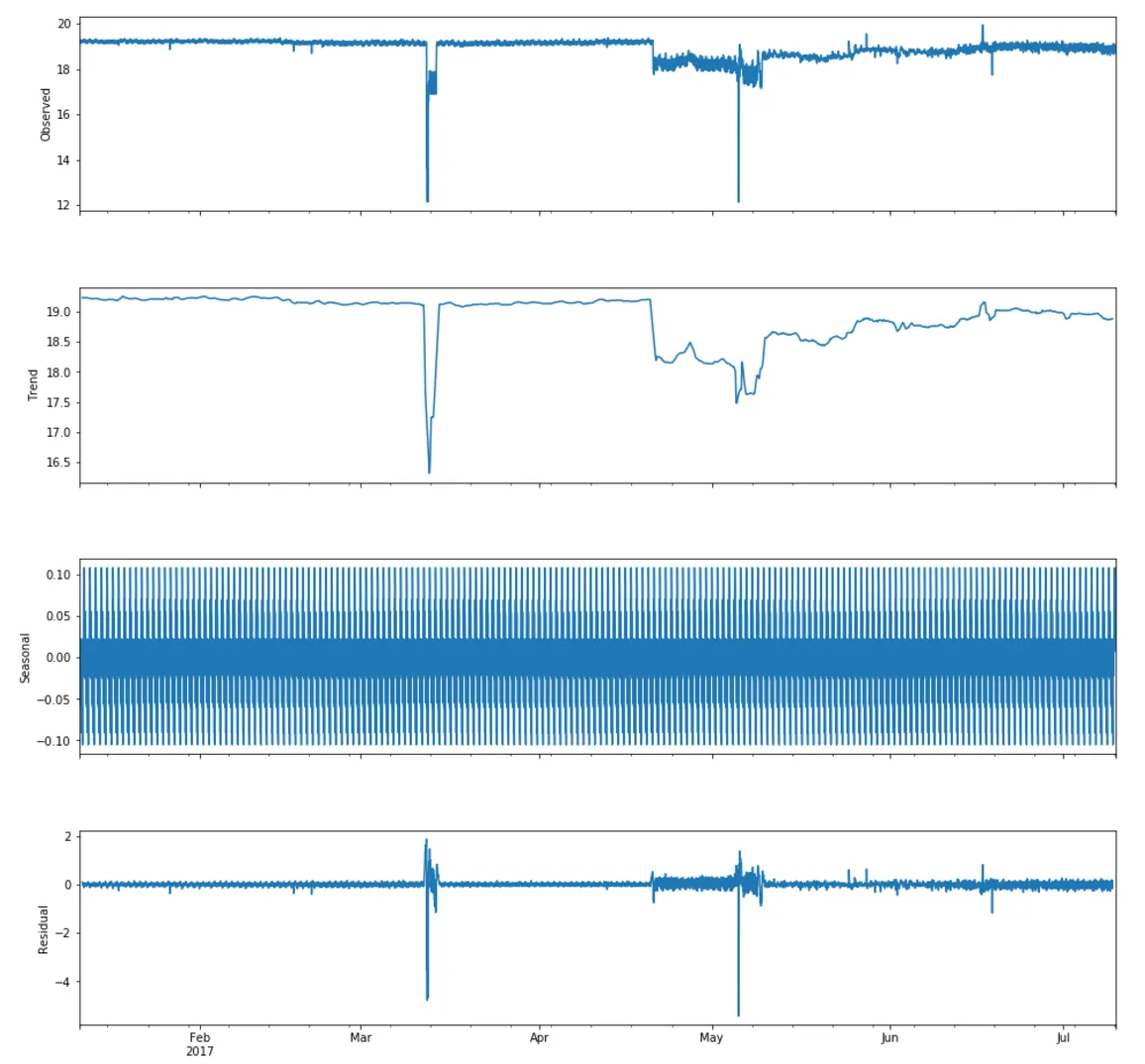
我想要理解这些图表,简短的描述将非常有帮助。我看到一开始没有趋势,过了一段时间后出现了上升趋势。我不确定我是否说得正确?我想要了解如何正确地读取这些图表,请给出一些好的描述。
当我尝试应用Dickey-Fuller测试来检查我的数据是否平稳以及是否需要进一步差分时,我得到了以下结果:
Test Statistic -4.117543
p-value 0.000906
Lags Used 30.000000
Number of Observations Used 4289.000000
Critical Value (1%) -3.431876
Critical Value (5%) -2.862214
Critical Value (10%) -2.567129
我提供两个链接以了解此问题:http://www.seanabu.com/2016/03/22/time-series-seasonal-ARIMA-model-in-python/和另一个链接。前者表示当测试统计量大于临界值时,数据是平稳的;而后者则相反。我对此感到困惑,我还参考了otexts.org,它说我们应该根据p值进行检查。请建议如何解释ADF测试给出的结果?
此外,当我尝试在数据集上应用ARIMA模型时:
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(df.y, order=(0,1,0))
model_fit = model.fit()
我的数据框中有一个日期时间列作为索引,y列具有浮点值。当我在这个数据框上应用模型时,会出现以下错误:
IndexError: 列表索引超出范围。
当我尝试使用以下命令打印模型摘要时,此错误就会出现:
print(model_fit.summary())
请帮我解决这个问题,以便我更好地理解ARIMA。