我已经使用这个命令大约一个到两个小时了,我担心自己可能失去了客观性。目标是仅匹配给定给Bash的相对文件路径。
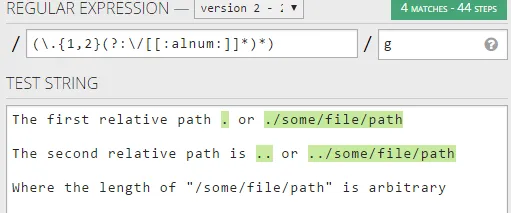
第一个相对路径是"."或"./some/file/path"。
第二个相对路径是".."或"../some/file/path"。
其中"/some/file/path"的长度是任意的。
我一直在使用grep和bash尝试弄清楚如何将其实现到我的脚本中,以便我可以扩展它到它的绝对文件路径,以便"./some/file/path"或"../some/file/path"变成"/the/absolute/file/path";我已经搞清楚了。
我的问题是匹配相对路径。
我一直在使用的代码是:
根据我的教材,定量符号{n}只匹配前一个元素出现 n 次。但实际上它匹配的是 n 或更多次!我做错了什么?
第一个相对路径是"."或"./some/file/path"。
第二个相对路径是".."或"../some/file/path"。
其中"/some/file/path"的长度是任意的。
我一直在使用grep和bash尝试弄清楚如何将其实现到我的脚本中,以便我可以扩展它到它的绝对文件路径,以便"./some/file/path"或"../some/file/path"变成"/the/absolute/file/path";我已经搞清楚了。
我的问题是匹配相对路径。
我一直在使用的代码是:
echo "../some/file/path" | egrep '\.{1}/?[[:graph:]]?+$'
并且
echo "../some/file/path" | egrep '\.{2}/?[[:graph:]]?+$'
我已经缩小了我的问题范围,发现问题与IT技术有关。
echo ".." | egrep '\.{2}'
只要出现了2 + n次,点号就会匹配,不一定是恰好2次。当我将其更改为
echo ".." | egrep '\.{1}'
出于某些我无法想象的原因,此处仍然会匹配成功。
最终的实现应该像这样工作:
41 _expand_relative_path () {
42 if [[ "$1" =~ ^\.{1}/?[[:graph:]]?+$ ]]; then
43 echo "."
44 elif [[ "$1" =~ ^\.{2}/?[[:graph:]]?+$ ]]; then
45 echo ".."
46 else
47 echo "$1"
48 fi
49 }
根据我的教材,定量符号{n}只匹配前一个元素出现 n 次。但实际上它匹配的是 n 或更多次!我做错了什么?
[^/].*。 - n. m.