file.readlines() 只会在操作系统支持通用换行符时,根据 \n、\r 或 \r\n 进行拆分。
U+0085 NEXT LINE (NEL) 在这种情况下不被视为换行符,因此您无需采取任何特殊措施使 file.readlines() 忽略它。
引用 open() 函数文档:
Python通常支持通用换行符; 提供
'U'将文件打开为文本文件,但行可能以以下任何一种方式终止: Unix行末约定
'\n'、Macintosh约定
'\r'或Windows约定
'\r\n'。 所有这些外部表示均被Python程序视为
'\n'。 如果Python没有使用通用换行符支持,则带
'U'的模式与普通文本模式相同。 请注意,因此打开的文件对象还具有名为newlines的属性,该属性的值为None(如果尚未看到换行符),
'\n',
'\r',
'\r\n'或包含所有已看到的换行符类型的元组。
和
通用换行符词汇表条目:
一种解释文本流的方式,其中以下所有内容都被认为是结束行:Unix换行约定
'\n',Windows约定
'\r\n'和旧Macintosh约定
'\r'。请参见
PEP 278和
PEP 3116,以及
str.splitlines()用于附加使用。不幸的是,
codecs.open()违反了这个规则;
文档模糊地提到了所请求的特定编解码器:行结束符是使用编解码器的解码器方法实现的,如果
keepends为真,则包括在列表条目中。
使用io.open()代替codecs.open(),以正确的编码打开文件,然后逐行处理:
with io.open(filename, encoding=correct_encoding) as f:
lines = f.open()
io 是 Python 3 中完全替代 Python 2 系统的新 I/O 基础设施。它仅处理 \n、\r 和 \r\n:
>>> open('/tmp/test.txt', 'wb').write(u'Line 1 \x85 Line 1.1\r\nLine 2\r\nLine 3\r\n'.encode('utf8'))
>>> import codecs
>>> codecs.open('/tmp/test.txt', encoding='utf8').readlines()
[u'Line 1 \x85', u' Line 1.1\r\n', u'Line 2\r\n', u'Line 3\r\n']
>>> import io
>>> io.open('/tmp/test.txt', encoding='utf8').readlines()
[u'Line 1 \x85 Line 1.1\n', u'Line 2\n', u'Line 3\n']
codecs.open() 的结果是由于代码使用了
str.splitlines(),而该方法存在文档错误;当分割 Unicode 字符串时,它会根据 Unicode 标准认为的任何换行符进行分割(这是一个相当复杂的问题
quite a complex issue)。该方法的文档未能充分解释这一点;它声称仅按照通用换行规则进行分割。
has a documentation bug
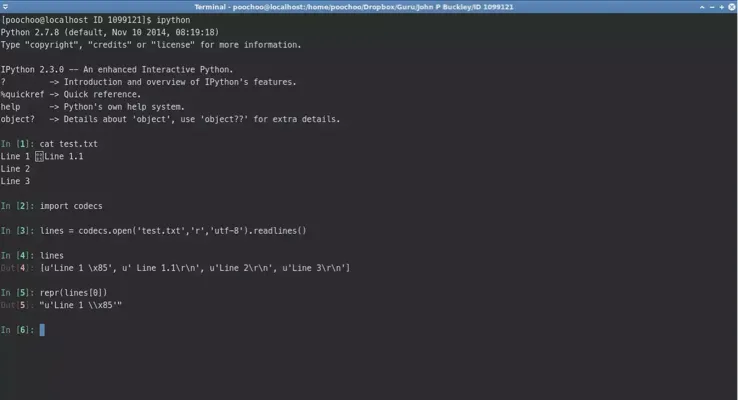
NEL(U+0085)不是readlines()支持的字符。 - Martijn Pieters