我有两个表格,使用连接查询从这两个表中获取公共记录。我已经使用以下查询,但我的问题是我得到了重复的记录。查询如下:
SELECT * FROM pos_metrics pm INNER JOIN pos_product_selling pps ON
pm.p_id=pps.p_id WHERE pm.p_id='0' AND pps.pos_buying_id='0' AND pm.type=1
pos_metrics表:
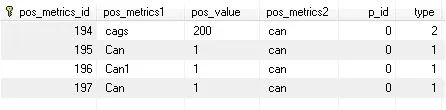
pos_product_selling表:

输出结果:

编辑:
当我尝试同时使用GROUP BY和DISTINCT时,没有获得重复的数据,但是第二个表中的值重复了。是否还有其他解决方案?