我试图在一个字符串中找到最长的回文串。暴力解法需要O(n^3)的时间。我读到了用后缀树可以实现线性时间算法。我熟悉后缀树,也能够很好的构建它们。那么如何使用构建好的后缀树来找到最长的回文串。
使用后缀树查找字符串中最长回文字符串
49
- shreyasva
9
5暴力算法只需要 O(N^2) 的时间。 - tskuzzy
1这不是上面链接的重复。请尝试理解问题。上面问题中的答案最多只能给出一个超线性算法,而没有后缀树。我正在寻找一种使用后缀树的O(n)解决方案。 - shreyasva
1我无法投票重新开放,但这不是重复的问题!!! 这是一个特定的面试问题,面试官首先期望后缀树(与其他答案无关)和一个直观的解释如何工作。 不是100行代码,也不是有关如何尽快在10亿个ACGT的基因序列中找到回文的整个理论(http://johanjeuring.blogspot.com/2007/08/finding-palindromes.html)... - Ricky Bobby
5在查看评论对话后重新开放。 - Tim Post
@RikayanBandyopadhyay,你说得对。这些观点表述得不好。但是链接的论文很好。 - cdunn2001
显示剩余4条评论
5个回答
31
Linear解法如下:
前提条件:
(1).你必须知道如何在O(N)或O(NlogN)时间内构建后缀数组
(2).你必须知道如何找到标准的LCP数组即相邻后缀i和i-1之间的LCP
即 LCP [i]=LCP(suffix i在已排序的数组中, suffix i-1在已排序的数组中),其中(i>0)。
假设原始字符串为S,反转后的字符串为S'。 以S="banana"为例,那么它的反转字符串是S'=ananab。
步骤1: 将S + # + S'连接起来得到字符串Str,其中#是原始字符串中不存在的字母。
Concatenated String Str=S+#+S'
Str="banana#ananab"
步骤2:现在构建字符串Str的后缀数组。
在这个例子中,后缀数组是:
Suffix Number Index Sorted Suffix
0 6 #ananab
1 5 a#ananab
2 11 ab
3 3 ana#ananab
4 9 anab
5 1 anana#ananab
6 7 ananab
7 12 b
8 0 banana#ananab
9 4 na#ananab
10 10 nab
11 2 nana#ananab
12 8 nanab
即:SuffixArray[]={6,5,11,3,9,1,7,12,0,4,10,2,8}; 步骤3:既然您已成功构建了后缀数组,请找出相邻后缀之间的最长公共前缀。
LCP between #ananab a#ananab is :=0
LCP between a#ananab ab is :=1
LCP between ab ana#ananab is :=1
LCP between ana#ananab anab is :=3
LCP between anab anana#ananab is :=3
LCP between anana#ananab ananab is :=5
LCP between ananab b is :=0
LCP between b banana#ananab is :=1
LCP between banana#ananab na#ananab is :=0
LCP between na#ananab nab is :=2
LCP between nab nana#ananab is :=2
LCP between nana#ananab nanab is :=4
因此,LCP数组为LCP={0,0,1,1,3,3,5,0,1,0,2,2,4}。
其中 LCP[i]=后缀i和(i-1)的最长公共前缀长度。(对于 i>0)
步骤4:
现在您已经构建了一个LCP数组,请使用以下逻辑。
Let the length of the Longest Palindrome ,longestlength:=0 (Initially)
Let Position:=0.
for(int i=1;i<Len;++i)
{
//Note that Len=Length of Original String +"#"+ Reverse String
if((LCP[i]>longestlength))
{
//Note Actual Len=Length of original Input string .
if((suffixArray[i-1]<actuallen && suffixArray[i]>actuallen)||(suffixArray[i]<actuallen && suffixArray[i-1]>actuallen))
{
//print :Calculating Longest Prefixes b/w suffixArray[i-1] AND suffixArray[i]
longestlength=LCP[i];
//print The Longest Prefix b/w them is ..
//print The Length is :longestlength:=LCP[i];
Position=suffixArray[i];
}
}
}
So the length of Longest Palindrome :=longestlength;
and the longest palindrome is:=Str[position,position+longestlength-1];
执行示例:
actuallen=Length of banana:=6
Len=Length of "banana#ananab" :=13.
Calculating Longest Prefixes b/w a#ananab AND ab
The Longest Prefix b/w them is :a
The Length is :longestlength:= 1
Position:= 11
Calculating Longest Prefixes b/w ana#ananab AND anab
The Longest Prefix b/w them is :ana
The Length is :longestlength:= 3
Position:=9
Calculating Longest Prefixes b/w anana#ananab AND ananab
The Longest Prefix b/w them is :anana
The Length is :longestlength:= 5
Position:= 7
So Answer =5.
And the Longest Palindrome is :=Str[7,7+5-1]=anana
只需做个笔记::
第4步中的if条件基本上是指,在每次迭代(i)中,如果我取后缀s1(i)和s2(i-1),那么“s1必须包含#且s2不能包含#”或者“s2必须包含#且s1不能包含#”。
|(1:BANANA#ANANAB)|leaf
tree:|
| | | |(7:#ANANAB)|leaf
| | |(5:NA)|
| | | |(13:B)|leaf
| |(3:NA)|
| | |(7:#ANANAB)|leaf
| | |
| | |(13:B)|leaf
|(2:A)|
| |(7:#ANANAB)|leaf
| |
| |(13:B)|leaf
|
| | |(7:#ANANAB)|leaf
| |(5:NA)|
| | |(13:B)|leaf
|(3:NA)|
| |(7:#ANANAB)|leaf
| |
| |(13:B)|leaf
|
|(7:#ANANAB)|leaf
- Ritesh Kumar Gupta
4
2我必须说讲解非常棒。谢谢,它帮助我解决了Spoj问题LPS。 - user1134599
8谢谢您的解释。对于这种情况:1234xaba4321,这个算法会选择1234或者4321作为结果,而不是aba吗? - poiu2000
@poiu2000,第4步中的if条件基本上是指,在每次迭代(i)中,如果我取后缀s1(i)和s2(i-1),那么,“s1必须包含#且s2不得包含#”或“s2必须包含#且s1不得包含#”。 - Cem
1严格来说,这个答案使用的是后缀数组而不是后缀树,这并没有真正回答问题。 - pterodragon
23
我认为你需要按照以下步骤进行:
设y1y2...yn是你的字符串(其中yi代表字母)。
创建Sf=y1y2...yn$和Sr=ynyn-1...y1#的广义后缀树(将字母反转并选择不同的结束字符用于Sf($)和Sr(#),其中Sf表示“正向字符串”,Sr表示“反向字符串”)。
对于Sf中的每个后缀i,找到它与Sr中后缀n-i+1的最近公共祖先。
从根结点到最近公共祖先的路径是一个回文串,因为现在最近公共祖先代表这两个后缀的最长公共前缀。请注意:
(1) 后缀的前缀是子串。
(2) 回文串是与其反转相同的字符串。
(3) 因此,字符串中包含的最长回文串正好是该字符串及其反转的最长公共子串。
(4) 因此,一个字符串中最长的回文子串恰好是该字符串与其反转后所有后缀对之间的最长公共前缀。这就是我们在这里做的事情。
示例
让我们来看看单词banana。
Sf = banana$
Sr = ananab#
下面是Sf和Sr的广义后缀树,其中每个路径末尾的数字是对应后缀的索引。Blue_4的父节点所有3个分支共同拥有的a应该在其进入边旁边的n上,这里有一个小错误:
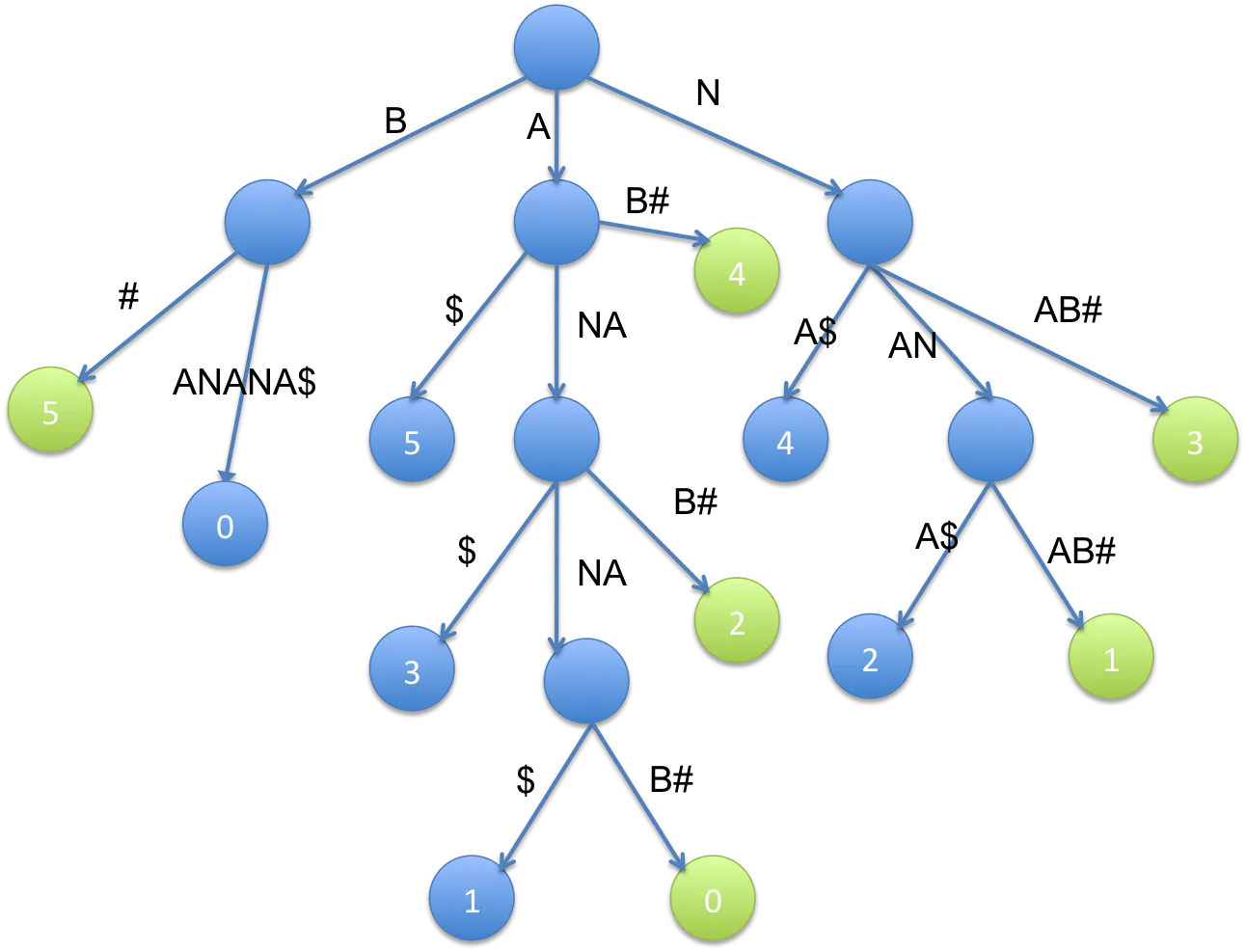
树中最低的内部节点是该字符串及其反转的最长公共子串。因此,查看树中的所有内部节点,您将找到最长的回文子串。
最长的回文子串位于Green_0和Blue_1之间(即banana 和 anana),为anana
编辑
我刚刚发现了这篇文章,它回答了这个问题。
- Ricky Bobby
15
1嗨,你是用什么工具制作了那张精美的图片呢? - Tomas
13你确定你的第三和第四个说法吗?例如,字符串:xyztuvananakvutzyx及其反转xyztuvkananavutzyx具有xyztuv作为它们最长公共前缀,但xyztuv不是回文。 - CEGRD
3请修改这个答案。我认为你只需要检查回文字符串的长度加上正向字符串中的起始索引和反向字符串中的起始索引是否等于原始字符串的长度即可。 - Neil G
4-1. 这个答案是错误的,正如CEGRD所指出的那样。声明3和4是不成立的。你应该认真修复或删除这个答案。 - Thorkil Holm-Jacobsen
1第三项(因此第四项)声明是不正确的。反例:字符串“abcdba”中包含的最长回文是单个字母,但是“abcdba”和其反转“abdcba”的最长公共子串是“ab”(即2个字母)。 - Ofer Magen
显示剩余10条评论
7
几年过去了...
假设字符串s是原始字符串,r是s反转后的字符串。我们还假设已经完全构建了一个后缀树ST,使用s。
下一步是将r的所有后缀与ST进行比较。对于r的每个新后缀,我们将维护我们成功匹配前k个字符的计数,这些字符与树中的现有后缀(即s的后缀之一)匹配。
例如,假设我们正在匹配r的后缀“RAT”,而s包含以“RA”开头的一些后缀,但没有与“RAT”匹配的后缀。当我们最终不得不放弃最后一个字符“T”时,k将等于2。我们将r的后缀的前两个字符与s的后缀的前两个字符进行匹配。我们将到达的节点称为n。
现在,我们如何知道何时找到回文?通过检查n下的所有叶节点。
在传统的后缀树中,每个后缀的起始索引存储在该后缀分支的叶子节点中。在上面的示例中,s可能包含以“RA”开头的一堆后缀,其中每个后缀都从n的叶节点后代中的一个索引开始。
让我们使用这些索引。
如果我们将R的一个子字符串的k个字符与ST中的k个字符进行匹配,这意味着什么?这只是意味着我们找到了一些反转的字符串。但是,如果R中子字符串开始的位置等于S中匹配的子字符串加上k,那么这意味着s[i]到s[i+k]与s[i+k]到s[i]相同!因此,按定义,我们已经找到了大小为k的回文。
现在,您只需要跟踪到目前为止找到的最长回文,并在函数结束时返回它即可。
假设字符串s是原始字符串,r是s反转后的字符串。我们还假设已经完全构建了一个后缀树ST,使用s。
下一步是将r的所有后缀与ST进行比较。对于r的每个新后缀,我们将维护我们成功匹配前k个字符的计数,这些字符与树中的现有后缀(即s的后缀之一)匹配。
例如,假设我们正在匹配r的后缀“RAT”,而s包含以“RA”开头的一些后缀,但没有与“RAT”匹配的后缀。当我们最终不得不放弃最后一个字符“T”时,k将等于2。我们将r的后缀的前两个字符与s的后缀的前两个字符进行匹配。我们将到达的节点称为n。
现在,我们如何知道何时找到回文?通过检查n下的所有叶节点。
在传统的后缀树中,每个后缀的起始索引存储在该后缀分支的叶子节点中。在上面的示例中,s可能包含以“RA”开头的一堆后缀,其中每个后缀都从n的叶节点后代中的一个索引开始。
让我们使用这些索引。
如果我们将R的一个子字符串的k个字符与ST中的k个字符进行匹配,这意味着什么?这只是意味着我们找到了一些反转的字符串。但是,如果R中子字符串开始的位置等于S中匹配的子字符串加上k,那么这意味着s[i]到s[i+k]与s[i+k]到s[i]相同!因此,按定义,我们已经找到了大小为k的回文。
现在,您只需要跟踪到目前为止找到的最长回文,并在函数结束时返回它即可。
- sgarza62
7
你能解释一下为什么之前的答案是错误的吗? - templatetypedef
1这是一个非常简单的解决方案,似乎是正确的,但是为什么其他答案如此复杂呢?甚至包括 @zsoltsafrany 的那个,他描述了 Skiena 书中的解决方案。 - max
2我对所有错误答案的点赞感到有些震惊。人们在点赞之前是否会思考呢? - Amtrix
1终于有一个正确的后缀树算法了。而且解释得很好。 - RaphaMex
1我在想这个算法的复杂度。构建后缀树:_O(n)_。枚举反向后缀:_O(n)_。将每个反向后缀适配到树中:_O(n)_。因此,总体而言,这将产生 O(n+n*n) 的时间复杂度。正确吗? - ngmir
显示剩余2条评论
2
使用后缀树查找S中的最长回文串 - 回文串是一种字符串,如果字符顺序被反转,则读起来相同,例如madam。要在字符串S中查找最长回文串,请构建一个包含S的所有后缀和S的反转的单个后缀树,并将每个叶子标识为其起始位置。此树中任何具有正向和反向孩子的节点都定义为回文。
- Zsolt Safrany
-3
动态规划解决方案:
int longestPalin(char *str)
{
n = strlen(str);
bool table[n][n]l
memset(table, 0, sizeof(table));
int start = 0;
for(int i=0; i<n; ++i)
table[i][i] = true;
int maxlen = 1;
for(int i=0; i<n-1; ++i)
{
if(str[i] == str[i+1])
{
table[i][i] = true;
start = i;
maxlen = 2;
}
}
for(int k=3; k<=n; ++k)
{
for(int i=0; i<n-k+1; ++i)
{
int j = n+k-1;
if(str[i] == str[j] && table[i+1][j-1])
{
table[i][j] = true;
if(k > maxlen)
{
start = i;
maxlen = k;
}
}
}
}
print(str, start, start+maxlen-1);
return maxlen;
}
- user3166594
1
问题是“使用后缀树”,而不是DP。 - Zsolt Safrany
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接