我如何获得如下所示的依赖树。 我可以获得纯文本形式的依赖关系,也可以借助dependencysee工具获得依赖图。但是对于以单词为节点和依赖关系为边的依赖树,该怎么办?非常感谢!
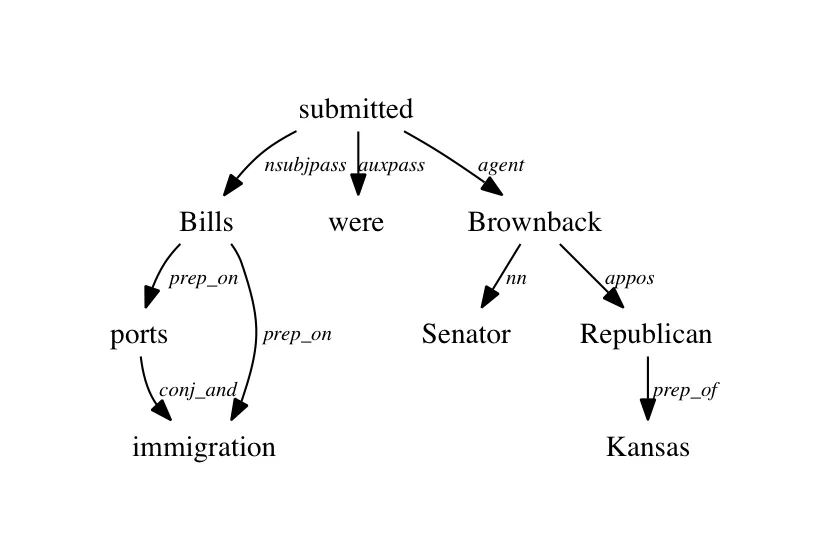
我如何获得如下所示的依赖树。 我可以获得纯文本形式的依赖关系,也可以借助dependencysee工具获得依赖图。但是对于以单词为节点和依赖关系为边的依赖树,该怎么办?非常感谢!
edu.stanford.nlp.trees.semgraph.SemanticGraph中找到一个toDotFormat()方法,它将把SemanticGraph转换为dot输入语言格式,可以由dot/GraphViz渲染。目前没有提供此功能的命令行工具,但使用该方法相当简单。以下是您如何(使用Python)完成此操作:
安装所有必需的依赖项(OS X):
# assuming you have java installed and available in PATH
# and homebrew installed
brew install stanford-parser
brew install graphviz
pip install nltk
pip install graphviz
代码:
import os
from nltk.parse.stanford import StanfordDependencyParser
from graphviz import Source
# make sure nltk can find stanford-parser
# please check your stanford-parser version from brew output (in my case 3.6.0)
os.environ['CLASSPATH'] = r'/usr/local/Cellar/stanford-parser/3.6.0/libexec'
sentence = 'The brown fox is quick and he is jumping over the lazy dog'
sdp = StanfordDependencyParser()
result = list(sdp.raw_parse(sentence))
dep_tree_dot_repr = [parse for parse in result][0].to_dot()
source = Source(dep_tree_dot_repr, filename="dep_tree", format="png")
source.view()
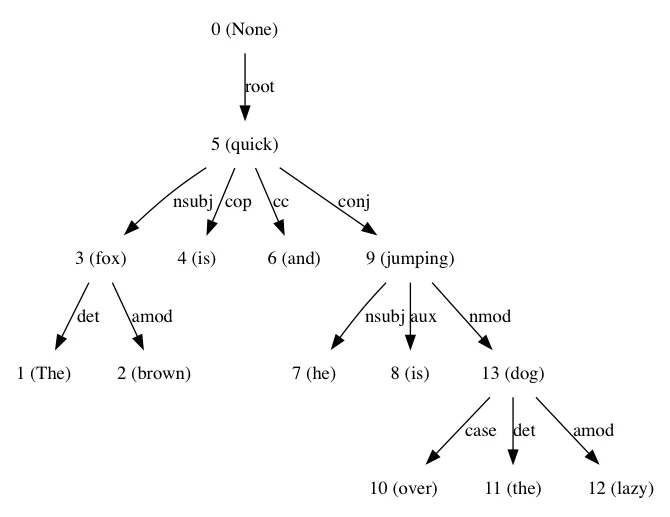
我在阅读Python文本分析时使用了这个工具:第三章,非常好的阅读材料,如果您需要更多关于依存句法分析的信息,请参考。
Parse the sentence:
sent = 'What is the step by step guide to invest in share market in india?'
p = dep_parser.raw_parse(sent)
for e in p:
p = e
break
Print the .to_dot() format as:
print(p.to_dot())
Copy paste the output to http://graphs.grevian.org/graph and press the Generate button.
我目前正在处理类似的问题。这不是一个理想的解决方案,但可能会有所帮助。如上面的答案中所提到的,使用toDotFormat()获取点语言中的解析树。然后使用众多工具之一(我正在使用python-graph)读取此数据并将其呈现为图片。在此链接中有一个示例http://code.google.com/p/python-graph/wiki/Example