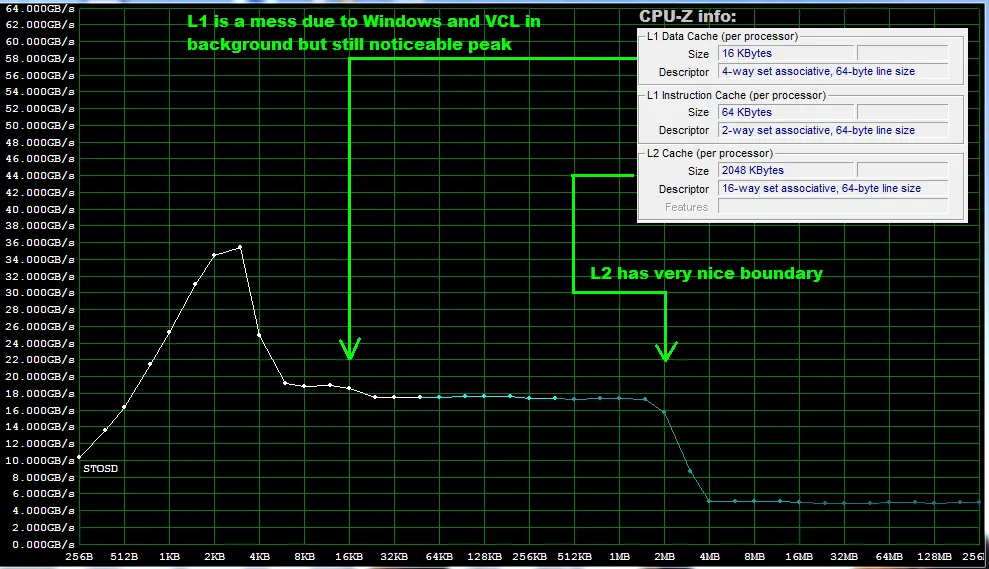
我从这个链接 (https://gist.github.com/jiewmeng/3787223) 获取了这个程序。我一直在网上搜索,想更好地理解处理器缓存(L1和L2)。我想编写一个程序,使我能够猜测我的新笔记本电脑的L1和L2缓存大小。(仅供学习目的。我知道我可以查看规格。)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define KB 1024
#define MB 1024 * 1024
int main() {
unsigned int steps = 256 * 1024 * 1024;
static int arr[4 * 1024 * 1024];
int lengthMod;
unsigned int i;
double timeTaken;
clock_t start;
int sizes[] = {
1 * KB, 4 * KB, 8 * KB, 16 * KB, 32 * KB, 64 * KB, 128 * KB, 256 * KB,
512 * KB, 1 * MB, 1.5 * MB, 2 * MB, 2.5 * MB, 3 * MB, 3.5 * MB, 4 * MB
};
int results[sizeof(sizes)/sizeof(int)];
int s;
/*for each size to test for ... */
for (s = 0; s < sizeof(sizes)/sizeof(int); s++)
{
lengthMod = sizes[s] - 1;
start = clock();
for (i = 0; i < steps; i++)
{
arr[(i * 16) & lengthMod] *= 10;
arr[(i * 16) & lengthMod] /= 10;
}
timeTaken = (double)(clock() - start)/CLOCKS_PER_SEC;
printf("%d, %.8f \n", sizes[s] / 1024, timeTaken);
}
return 0;
}
我的机器上程序的输出如下。如何解释这些数字?这个程序对我说了什么?
1, 1.07000000
4, 1.04000000
8, 1.06000000
16, 1.13000000
32, 1.14000000
64, 1.17000000
128, 1.20000000
256, 1.21000000
512, 1.19000000
1024, 1.23000000
1536, 1.23000000
2048, 1.46000000
2560, 1.21000000
3072, 1.45000000
3584, 1.47000000
4096, 1.94000000