如何为最小团覆盖算法生成非平凡的测试用例?
换句话说,我想生成一个图,其中最小数量的团和每个节点分配到一个团的情况事先已知。
谢谢!
换句话说,我想生成一个图,其中最小数量的团和每个节点分配到一个团的情况事先已知。
谢谢!
算法
输入I,即交叉数(即覆盖图中每个顶点所需的最小团数)。
输入ni个数字,表示I个团中每个团的顶点数。每个数字必须大于等于3。
构建I个顶点{ VI },并将它们连接成一个环,使得每个顶点与其他两个顶点相连。
循环i,遍历I个团:
随机化顶点和连接的顺序(以隐藏构造过程)
C++实现
#include <string>
#include <fstream>
#include <sstream>
#include <iostream>
#include <vector>
#include <map>
#include <algorithm>
#include "../PathFinder/src/cGraph.h" // https://github.com/JamesBremner/PathFinder
int intersectionNumber;
std::vector<int> vCliqueCount;
raven::graph::cGraph g;
void input()
{
std::cout << "Intersection Number: ";
std::cin >> intersectionNumber;
std::cout << "clique counts:\n";
for (int i = 0; i < intersectionNumber; i++)
{
int cc;
std::cout << "#" << i+1 << ": ";
std::cin >> cc;
vCliqueCount.push_back(cc);
}
}
void generate()
{
std::string previs;
std::vector<std::string> vsclique;
for (int i = 0; i < intersectionNumber; i++)
{
auto is = std::to_string(i);
auto is0 = is+"_0";
if (i > 0)
g.add(is0, previs);
previs = is0;
vsclique.clear();
for( int c1 = 0; c1 < vCliqueCount[i]-1; c1++ ) {
vsclique.push_back(is+"_"+std::to_string(c1+1));
g.add( is0,vsclique.back());
}
for( int c1 = 0; c1 < vsclique.size(); c1++ )
{
for( int c2 = c1+1; c2 < vsclique.size(); c2++ )
g.add(vsclique[c1],vsclique[c2]);
}
}
if( intersectionNumber>2)
g.add("0_0", previs);
}
void output()
{
std::ofstream ifs("gengraph.txt");
if( ! ifs.is_open())
throw std::runtime_error("Cannot open output");
auto vl = g.edgeList();
// this outputs vertex names that reveal the clique each vertex belongs to
// for( auto& l : vl )
// {
// ifs << "l " << g.userName(l.first)
// <<" "<<g.userName(l.second)<< "\n";
// }
// this outputs obscured graph construction
std::random_shuffle( vl.begin(),vl.end());
std::map<int,int> obvertex;
int kv = 0;
for( auto& l : vl )
{
obvertex.insert(std::make_pair(l.first,kv++));
obvertex.insert(std::make_pair(l.second,kv++));
ifs << std::to_string(obvertex.find(l.first)->second)
<<" "<<std::to_string(obvertex.find(l.second)->second)<< "\n";
}
}
main()
{
input();
generate();
output();
return 0;
}
测试运行
输入
Intersection Number: 3
clique counts:
#1: 3
#2: 4
#3: 5
输出(已隐藏)
0 1
2 3
4 5
2 7
2 9
5 11
7 11
14 15
9 3
0 15
1 15
7 4
0 14
0 27
4 11
1 27
7 5
2 0
27 15
1 14
7 0
27 14
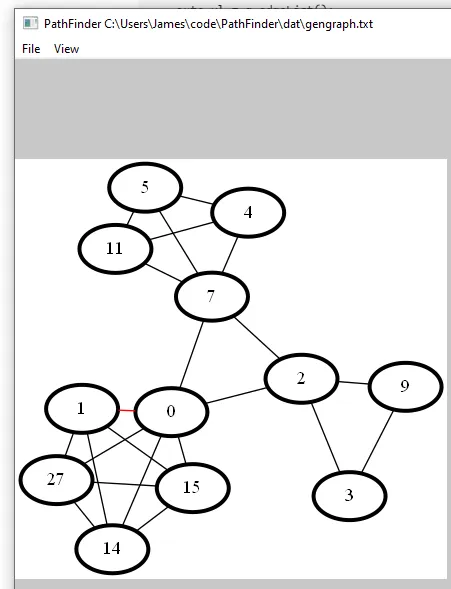
Windows版本:https://github.com/JamesBremner/genclique/releases/tag/v1.0.0
额外的边
为了进一步混淆团建设,我们可以在不降低交集数量的情况下,在不同团的顶点之间添加边。(@Dave的建议)
每个团中的顶点都有一个索引号。顶点标签的格式如下:"X_Y",其中X是团的索引,Y是团中的顶点索引,所有索引都从零开始计数。第零个顶点是在初始构建过程中与其他两个团的第零个顶点相连的顶点。现在,我们在其他顶点之间添加边,除了索引为0(已经与其他团相连)和1(为了防止交集数量减少)的顶点与其他团的顶点之间。
如果您查看GitHub存储库中的代码输出的未混淆图,可能更容易理解正在发生的情况。
以下是代码:
void extraEdges()
{
// loop over all cliques
for (int c1 = 0; c1 < intersectionNumber; c1++)
{
auto is = std::to_string(c1) + "_1";
// loop over other cliques, not already connected to c1
for (
int c2 = c1 + 1;
c2 < intersectionNumber;
c2++)
{
// loop over vertices on other clique, except numbers 0 and 1
for (int v = 2; v < vCliqueCount[c2]; v++)
{
auto sv2 = std::to_string(c2) + "_" + std::to_string(v);
g.add(is, sv2);
}
}
}
}
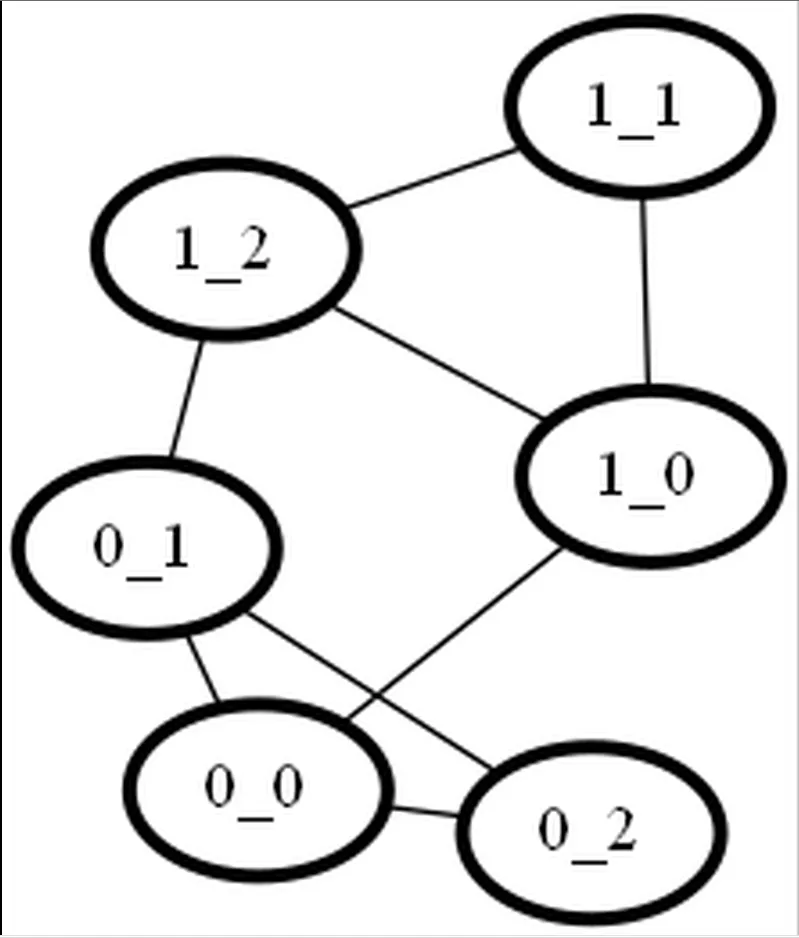 这是一个更大的构造布局(有遮挡)。
这是一个更大的构造布局(有遮挡)。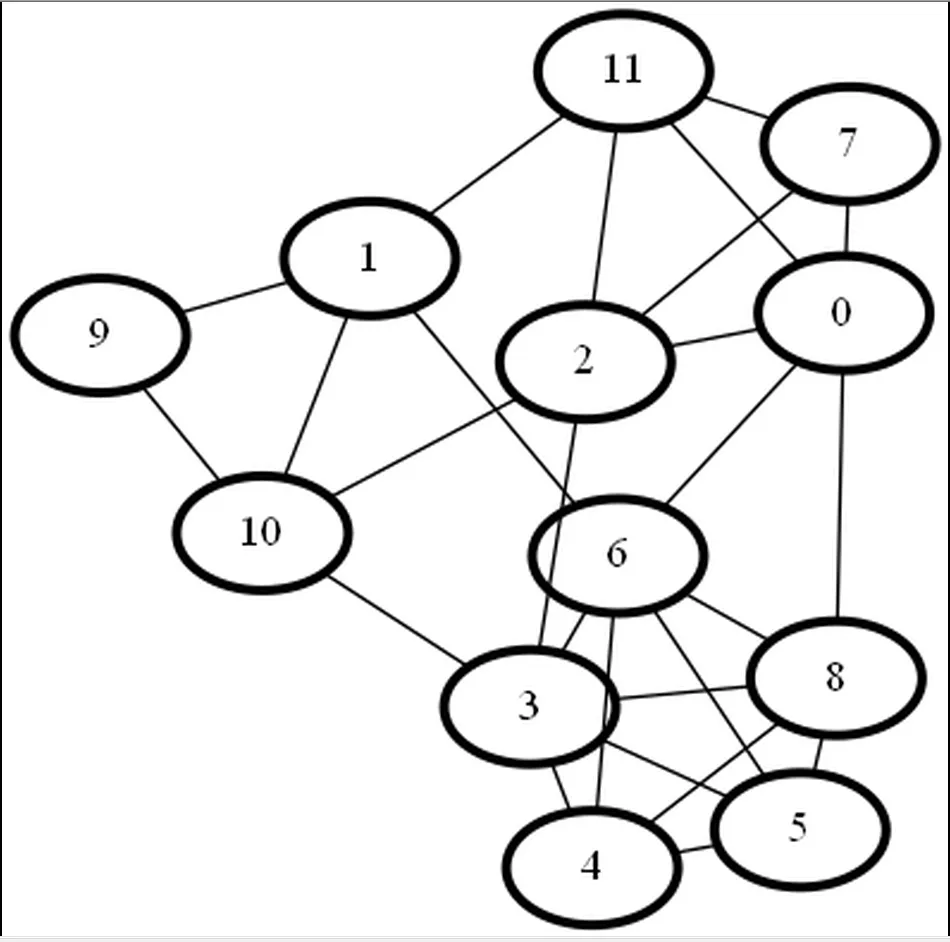
我在Rust中对团体发现做了很多工作。
总的来说,我发现当团体的大小大致相等时,寻找大小为k的覆盖是最困难的,所以在我的测试中,我生成了这样的团体。基本的方法是:
输入:
number of vertices (call this n),
number of cliques in the cover (call this k),
and the fraction of potential edges that exist (call this p).
Generate k approximately equal sized cliques (approximate in that some will be larger by 1 vertex if n%k != 0)
Calculate the remaining edges: p*choose(n, 2) - (edges used up by k cliques)
Randomly assign remaining edges to pairs of nonadjacent vertices.
fn get_random_graph_with_k_cliques(
num_vertices: usize,
cliques_ct: usize,
edge_probability: f64,
) -> Graph {
if cliques_ct == 0 {
return get_random_graph(num_vertices, edge_probability);
}
let mut ret_graph = Graph::new(num_vertices);
let mut edge_candidates_remaining = num_vertices * (num_vertices - 1) / 2;
let mut edges_remaining = (edge_candidates_remaining as f64 * edge_probability) as usize;
let reserved_edges = cliques_ct * (num_vertices / cliques_ct) * (num_vertices / cliques_ct - 1)
/ 2
+ (num_vertices % cliques_ct) * (num_vertices / cliques_ct);
edge_candidates_remaining -= reserved_edges;
if reserved_edges > edges_remaining {
edges_remaining = 0;
} else {
edges_remaining -= reserved_edges;
}
for i in 0..(ret_graph.size - 1) {
for j in (i + 1)..(ret_graph.size) {
if i % cliques_ct == j % cliques_ct {
ret_graph.vertices[i].neighbors_bv.set(j, true);
ret_graph.vertices[j].neighbors_bv.set(i, true);
} else if fastrand::f64() < (edges_remaining as f64) / (edge_candidates_remaining as f64) {
edges_remaining -= 1;
ret_graph.vertices[i].neighbors_bv.set(j, true);
ret_graph.vertices[j].neighbors_bv.set(i, true);
}
if i % cliques_ct != j % cliques_ct {
edge_candidates_remaining -= 1;
}
}
}
for i in 0..(ret_graph.size) {
if ret_graph.vertices[i].neighbors_bv.any() {
ret_graph.vertices[i].has_neighbors = true;
}
}
ret_graph.conform_cliques_to_vertices();
ret_graph
}