这都是UTF8编码的一部分(它只是Unicode的一种编码方案)。
可以通过检查第一个字节来确定大小,如下所示:
- 如果以位模式
"10" (0x80-0xbf)开头,则不是序列的第一个字节,应向后退回到找到开始的任何以"0"或"11"开头的字节(感谢Jeffrey Hantin在评论中指出这一点)。
- 如果以位模式
"0" (0x00-0x7f)开头,则为1个字节。
- 如果以位模式
"110" (0xc0-0xdf)开头,则为2个字节。
- 如果以位模式
"1110" (0xe0-0xef)开头,则为3个字节。
- 如果以位模式
"11110" (0xf0-0xf7)开头,则为4个字节。
我将重复显示此表格,但原始表格在维基百科UTF8页面此处。
+----------------+----------+----------+----------+----------+
| Unicode | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
+----------------+----------+----------+----------+----------+
| U+0000-007F | 0xxxxxxx | | | |
| U+0080-07FF | 110yyyxx | 10xxxxxx | | |
| U+0800-FFFF | 1110yyyy | 10yyyyxx | 10xxxxxx | |
| U+10000-10FFFF | 11110zzz | 10zzyyyy | 10yyyyxx | 10xxxxxx |
+----------------+----------+----------+----------+----------+
上表中的Unicode字符由以下比特构成:
000z-zzzz yyyy-yyyy xxxx-xxxx
假设 z 和 y 位在没有给出时都为0。由于以下原因,某些字节被视为非法的起始字节:
- 无用:以0xc0或0xc1开头的2字节序列实际上给出小于0x80的代码点,可以使用1字节序列更好地表示。
- 被RFC3629用于U+10FFFF以上的4字节序列、5字节和6字节序列。这些字节是0xf5到0xfd。
- 未使用:字节0xfe和0xff。
此外,在多字节序列中,不以"10"位开始的后续字节也是非法的。
例如,考虑序列[0xf4,0x8a,0xaf,0x8d]。由于第一个字节在0xf0和0xf7之间,这是一个4字节序列。
0xf4 0x8a 0xaf 0x8d
= 11110100 10001010 10101111 10001101
zzz zzyyyy yyyyxx xxxxxx
= 1 0000 1010 1011 1100 1101
z zzzz yyyy yyyy xxxx xxxx
= U+10ABCD
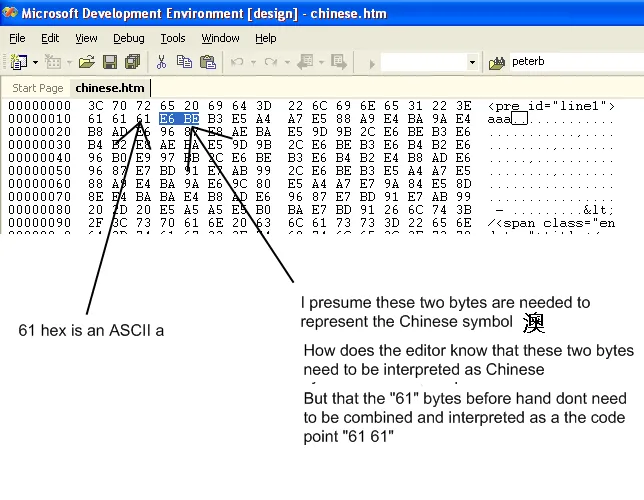
对于您特定的查询,第一个字节为0xe6(长度=3),字节序列如下:
0xe6 0xbe 0xb3
= 11100110 10111110 10110011
yyyy yyyyxx xxxxxx
= 01101111 10110011
yyyyyyyy xxxxxxxx
= U+6FB3
如果您在这里查找代码
,您会看到它是您在问题中提到的那个:澳。
为了展示解码是如何工作的,我回到了我的档案中找到了我的UTF8处理代码。我不得不对它进行一些改变,以使其成为一个完整的程序,并且已经删除了编码(因为问题实际上是关于解码的),所以我希望我没有从剪切和粘贴中引入任何错误:
#include <stdio.h>
#include <string.h>
#define UTF8ERR_TOOSHORT -1
#define UTF8ERR_BADSTART -2
#define UTF8ERR_BADSUBSQ -3
typedef unsigned char uchar;
static int getUtf8 (uchar *pBytes, int *pLen) {
if (*pLen < 1) return UTF8ERR_TOOSHORT;
if (pBytes[0] <= 0x7f) {
*pLen = 1;
return pBytes[0];
}
if (pBytes[0] <= 0xbf) return UTF8ERR_BADSTART;
if ((pBytes[0] == 0xc0) || (pBytes[0] == 0xc1)) return UTF8ERR_BADSTART;
if (pBytes[0] <= 0xdf) {
if (*pLen < 2) return UTF8ERR_TOOSHORT;
if ((pBytes[1] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
*pLen = 2;
return ((int)(pBytes[0] & 0x1f) << 6)
| (pBytes[1] & 0x3f);
}
if (pBytes[0] <= 0xef) {
if (*pLen < 3) return UTF8ERR_TOOSHORT;
if ((pBytes[1] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
if ((pBytes[2] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
*pLen = 3;
return ((int)(pBytes[0] & 0x0f) << 12)
| ((int)(pBytes[1] & 0x3f) << 6)
| (pBytes[2] & 0x3f);
}
if (pBytes[0] <= 0xf4) {
if (*pLen < 4) return UTF8ERR_TOOSHORT;
if ((pBytes[1] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
if ((pBytes[2] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
if ((pBytes[3] & 0xc0) != 0x80) return UTF8ERR_BADSUBSQ;
*pLen = 4;
return ((int)(pBytes[0] & 0x0f) << 18)
| ((int)(pBytes[1] & 0x3f) << 12)
| ((int)(pBytes[2] & 0x3f) << 6)
| (pBytes[3] & 0x3f);
}
return UTF8ERR_BADSTART;
}
static uchar htoc (char *h) {
uchar u = 0;
while (*h != '\0') {
if ((*h >= '0') && (*h <= '9'))
u = ((u & 0x0f) << 4) + *h - '0';
else
if ((*h >= 'a') && (*h <= 'f'))
u = ((u & 0x0f) << 4) + *h + 10 - 'a';
else
return 0;
h++;
}
return u;
}
int main (int argCount, char *argVar[]) {
int i;
uchar utf8[4];
int len = argCount - 1;
if (len != 4) {
printf ("Usage: utf8 <hex1> <hex2> <hex3> <hex4>\n");
return 1;
}
printf ("Input: (%d) %s %s %s %s\n",
len, argVar[1], argVar[2], argVar[3], argVar[4]);
for (i = 0; i < 4; i++)
utf8[i] = htoc (argVar[i+1]);
printf (" Becomes: (%d) %02x %02x %02x %02x\n",
len, utf8[0], utf8[1], utf8[2], utf8[3]);
if ((i = getUtf8 (&(utf8[0]), &len)) < 0)
printf ("Error %d\n", i);
else
printf (" Finally: U+%x, with length of %d\n", i, len);
return 0;
}
你可以按照以下方式使用你的字节序列来运行它(你需要4个字节,所以用0进行填充):
> utf8 f4 8a af 8d
Input: (4) f4 8a af 8d
Becomes: (4) f4 8a af 8d
Finally: U+10abcd, with length of 4
> utf8 e6 be b3 0
Input: (4) e6 be b3 0
Becomes: (4) e6 be b3 00
Finally: U+6fb3, with length of 3
> utf8 41 0 0 0
Input: (4) 41 0 0 0
Becomes: (4) 41 00 00 00
Finally: U+41, with length of 1
> utf8 87 0 0 0
Input: (4) 87 0 0 0
Becomes: (4) 87 00 00 00
Error -2
> utf8 f4 8a af ff
Input: (4) f4 8a af ff
Becomes: (4) f4 8a af ff
Error -3
> utf8 c4 80 0 0
Input: (4) c4 80 0 0
Becomes: (4) c4 80 00 00
Finally: U+100, with length of 2
{kind=link}
{kind=link}