我认为上述的隔离级别有很多相似之处。请问是否能给出一些好的例子来描述它们之间的主要区别?
SQL Server中“读取已提交”和“可重复读”有什么区别?
370
- Fore
1
4您应该详细说明问题,并添加“隔离级别”所属的标签(例如Java)。“隔离级别”是一个有些模糊不清的术语,您显然是在询问特定环境下的答案。请注意保持原文意思的前提下,尽可能使翻译内容通俗易懂。 - jesup
9个回答
802
读取提交是一种隔离级别,保证任何读取的数据在读取时都已经被提交。它简单地限制了读者看到任何中间的、未提交的“脏”读取。它不承诺如果事务重新发出读取,将找到相同的数据,数据在读取后可以自由更改。
可重复读是更高的隔离级别,除了读取提交级别的保证外,还保证任何读取的数据不能更改,如果事务再次读取相同的数据,它将在原地找到先前读取的数据,未更改且可供读取。
下一个隔离级别,可串行化,提供了更强的保证:除了可重复读取的所有保证外,它还保证后续读取不会看到任何新数据。
假设您有一个名为T的表格,其中包含一个C列并有一行,值为“1”。并考虑您有一个简单的任务如下:
BEGIN TRANSACTION;
SELECT * FROM T;
WAITFOR DELAY '00:01:00'
SELECT * FROM T;
COMMIT;
这是一个简单的任务,需要从表T中读取两次,它们之间有1分钟的延迟。
在READ COMMITTED下,第二个SELECT可能会返回任何数据。并发事务可能会更新记录、删除它或插入新记录。第二个select将始终看到新数据。
在REPEATABLE READ下,第二个SELECT保证至少显示从第一个SELECT返回的行不变。在那一分钟内,可以通过并发事务添加新行,但现有行不能被删除或更改。
在SERIALIZABLE下,第二个SELECT保证看到与第一个完全相同的行。没有行可以更改、删除,也没有并发事务可以插入新行。
如果你遵循上面的逻辑,你会很快意识到SERIALIZABLE事务虽然可能会让你的生活变得容易,但它们总是完全阻塞了每一个可能的并发操作,因为它们要求没有人可以修改、删除或插入任何行。.Net System.Transactions范围的默认事务隔离级别是可序列化的,这通常解释了结果的惨淡性能。
最后,还有快照隔离级别。快照隔离级别提供了与可序列化相同的保证,但不是通过要求没有并发事务可以修改数据来实现的。相反,它强制每个读者看到自己版本的世界(自己的“快照”)。这使得它非常易于编程,以及非常可扩展,因为它不会阻塞并发更新。然而,这种好处是有代价的:额外的服务器资源消耗。
补充阅读:
- Remus Rusanu
16
42我认为“可重复读”上面有误解:你说现有的行不能被删除或更改,但我认为它们可以被删除或更改,因为可重复读仅读取一个“快照”,而不是实际数据。从文档http://dev.mysql.com/doc/refman/5.0/en/set-transaction.html#isolevel_repeatable-read中可以看到:“在同一事务中的所有一致性读取都读取由第一次读取建立的快照。” - Derek Litz
3@Derek Litz,我的理解是:在交易进行时,第三方可以更改数据,但读取仍将看到“旧”的原始数据,就好像更改没有发生过一样(快照)。 - Programster
7@Cornstalks. 是的,删除(或插入)可以导致幻读。是的,在可重复读隔离级别下,幻读可能发生(仅来自插入操作)。不,从删除操作中产生的幻读在可重复读隔离级别下不会发生。测试一下。我所说的不与你引用的文档相矛盾。 - AndyBrown
7@Cornstalks NP。我之所以提到这个问题,是因为我自己也不确定,必须深入研究才能确定谁是正确的!而且我不想让未来的读者被误导。关于保留评论,最好按建议保留。我相信任何对细节感兴趣的人都会特别注意阅读所有评论!! - AndyBrown
17谢谢您没有删除您的评论。讨论有助于连接更多的信息点。 - Josh
显示剩余11条评论
92
可重复读
数据库的状态从事务开始时就被维护。如果你在session1中检索一个值,然后在session2中更新了该值,在session1中再次检索该值将返回相同的结果。读取是可重复的。
session1> BEGIN;
session1> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> BEGIN;
session2> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> UPDATE names SET firstname = 'Bob' WHERE id = 7;
session2> SELECT firstname FROM names WHERE id = 7;
Bob
session2> COMMIT;
session1> SELECT firstname FROM names WHERE id = 7;
Aaron
读取已提交
在事务的上下文中,您将始终检索到最近提交的值。如果您在session1中检索了一个值,在session2中更新它,然后再次在session1中检索它,您将获得作为session2中修改的该值。它会读取最后提交的行。
session1> BEGIN;
session1> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> BEGIN;
session2> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> UPDATE names SET firstname = 'Bob' WHERE id = 7;
session2> SELECT firstname FROM names WHERE id = 7;
Bob
session2> COMMIT;
session1> SELECT firstname FROM names WHERE id = 7;
Bob
懂了吗?
- Hazel_arun
5
我在SQL Server 2008中尝试使用“set isolation level repeatable read”进行可重复读取。创建了两个SQL查询窗口。但是没有起作用。为什么? - Aditya Bokade
1为什么第二个session1仍然会读出Aaron?难道session2的事务已经完成并提交了吗?我知道这很老了,但也许有人能够解释一下。 - Sonny Childs
19我认为可重复读会阻塞第二个会话直到第一个会话提交,所以这个例子是错误的。 - Nighon
5在可重复读的情况下,当第一会话读取行时,它会放置一个共享锁,这将不允许任何独占锁(给第二会话)进行更新,因此数据无法更新。 - Taher
2我认为在两个事务之间更新共享行时,SQL Server和MySQL的行为是不同的。 - user2488286
78
根据我阅读和理解这个线程以及@remus-rusanu的答案,简要回答如下:
有两个事务A和B。他们按照以下顺序执行以下操作。
- 事务B首先从表X读取
- 然后事务A写入表X
- 最后事务B再次从表X读取。
- ReadUncommitted: 事务B可以从事务A读取未提交的数据,并且根据A的写入可能会看到不同的行。完全没有锁定
- ReadCommitted: 事务B只能从事务A读取已提交的数据,并且根据仅提交的A写入可能会看到不同的行。 我们可以称之为简单锁吗?
- RepeatableRead: 事务B将读取与事务A无关的相同数据(行)。但是,事务A可以更改其他行。 行级阻塞
- Serializable: 事务B将像以前一样读取相同的行,而事务A不能读取或写入表格。 表级阻塞
- Snapshot: 每个事务都有自己的副本,并在其上工作。 每个人都有自己的视图
- Mo Zaatar
7
3这是最好的。 - Riding Cave
1非常简洁明了。我会用“交易”来替换“进程”这个词。 - Junaed
@Mo Zaatar,我们什么时候应该使用“表级块”?我认为“行级块”似乎已经足够应对所有的用例了。 - meallhour
这个答案存在一些问题,因为有一些不一致之处。我对答案进行了小的编辑,以使其更清晰,但仍然存在一些未解决的问题。在我解决这些问题之前,请告诉我如果我的编辑在某种程度上使答案变得更糟,请解释原因。 - FreelanceConsultant
解决问题:读取提交内容。 “我们可以称它为简单锁吗?”—为什么?据我所知,这里没有任何锁定。 - FreelanceConsultant
显示剩余2条评论
30
这是一个已经有被接受答案的问题,但我认为可以从SQL Server中锁定行为的角度来考虑这两个隔离级别。对于像我一样调试死锁的人可能会有所帮助。
READ COMMITTED (默认)
在SELECT语句中获取共享锁,当SELECT语句完成时释放锁。这就是系统如何保证没有读取未提交数据的脏读。其他事务仍然可以在SELECT完成和您的事务完成之间更改底层行。
REPEATABLE READ
在SELECT语句中获取共享锁,直到事务完成后才释放锁。这就是系统如何保证在事务完成前读取的值不会更改(因为它们会一直保持锁定直到事务完成)。
- Chris Gillum
4
1这是一个非常有趣的答案。 - Supun Wijerathne
这是否意味着可重复读与串行化是相同的?无论如何,回答很好。 - FreelanceConsultant
@自由职业顾问 从锁定的角度来看,它们非常相似。然而,在这里讨论了一些其他的差异 https://dev59.com/FmYr5IYBdhLWcg3w0tWE。使用可重复读与串行化时,具有幻读能力是其中提到的一个例子。 - Chris Gillum
是的,你的回答表明在“可重复读”中不可能出现幻读,这是不正确的。 - FreelanceConsultant
21
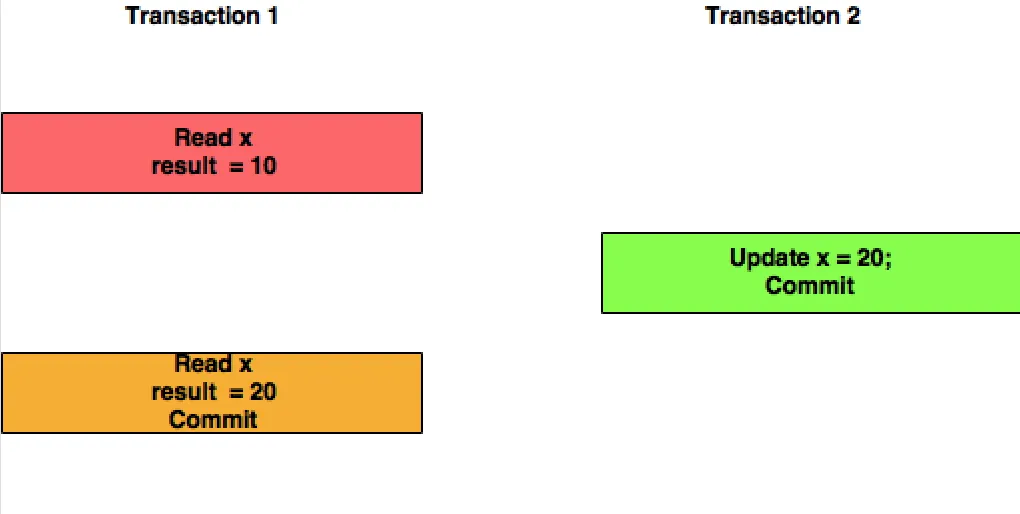
尝试通过简单的图解来解释这个疑惑。
读已提交:在这个隔离级别中,事务T1将会读取由事务T2提交的X的更新值。
可重复读:在这个隔离级别中,事务T1不会考虑事务T2提交的任何更改。
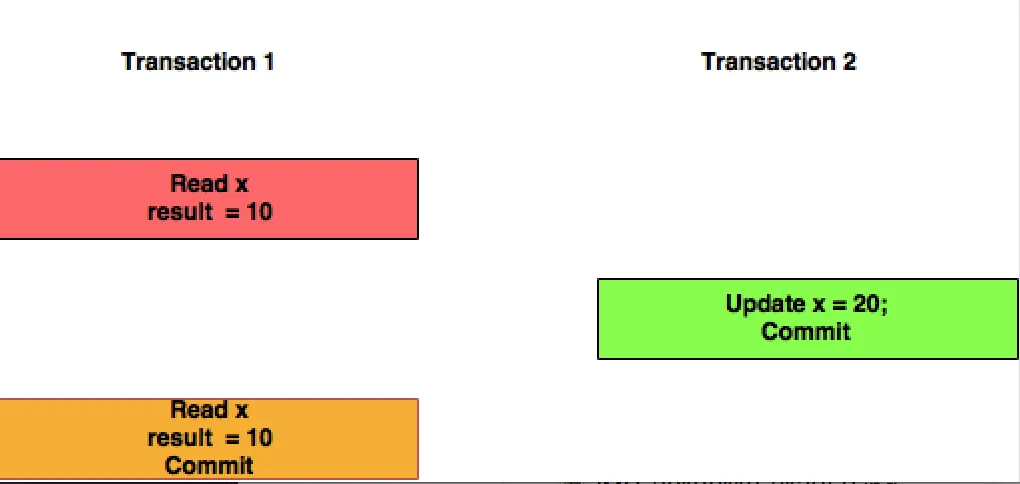
- vkrishna17
2
这里有其他答案,但它们没有提供任何关于底层数据库架构的详细信息,这使得理解事务隔离级别的功能方式以及解决了哪些问题变得困难。
并发环境中常见问题的概述
数据库系统允许多个并发连接。这导致了其他并发系统中出现的相同类型的问题。例如,在多线程环境中,互斥锁可以防止对内存的并发访问,从而解决了竞态条件问题,该问题可能导致数据损坏或无效。
类似地,因为数据库系统允许并发的CRUD操作(更新、插入、删除、选择),多个连接的并发操作可能会导致不良的观察行为。
请注意,数据库行操作的原子性可以防止直接数据损坏或不一致性,因此始终强制执行基本级别的事务隔离。
有关更多信息,请参见ACID。(原子性、一致性、隔离性、持久性。)简短的解释是,每行操作都是原子性的。这意味着防止数据损坏,因为它防止一种情况,即一个连接在另一个连接部分写入其数据之前,将一行数据的一部分写入,从而使另一个连接损坏该数据。 (对于熟悉多线程环境的人来说,这将更加直观。)
上述问题类似于多线程编程中出现的问题,其中一个线程开始向一块内存写入数据,然后另一个线程在第一个线程完成之前部分地将其数据写入相同的块,导致数据不一致。
首先了解行操作的原子性是很重要的,因为这已经提供了基本的保护级别。
事务隔离级别的类型
我们将看一下以下事务隔离级别,这些级别在MariaDB和许多其他SQL数据库实现中都可用。
我们首先需要知道不同的隔离级别是什么:
- 读未提交
- 读已提交
- 可重复读
- 串行化
事务隔离级别解决了哪些问题?
在解释这些不同选项的作用之前,重要的是要了解每个选项解决的问题。以下是潜在的不良行为列表。
- 脏读
- 不可重复读
- 幻读
脏读:
数据库操作通常被分组成一个事务。然后将此事务作为一组操作提交到数据库,或者执行回滚以丢弃该组操作。
如果一个连接开始了一系列操作作为一个事务,然后第二个连接开始从相同的表中读取数据,第二个连接可以从已经提交的数据库中读取数据,也可以读取作为打开但未提交的事务的一部分所做的更改。
这就定义了“读取已提交”和“读取未提交”的区别。
这在概念上是不寻常的,因为读取未提交的数据通常没有太多意义。事务的整个目的是确保数据库中的数据不会以这种方式发生更改。
总之:
- 连接A打开一个事务并开始排队修改(写入)操作
- 连接B以未提交读模式打开,并从数据库中读取数据
- 连接A继续排队更多的修改操作
- 如果连接B再次读取数据,则数据将已经发生了变化
- 如果连接A执行回滚,然后连接B执行另一个读取操作,则由于未提交数据的回滚,所读取的数据将会发生变化
- 这被称为脏读
- 通常情况下,您不必担心这种情况,因为作为一般规则,您可能不应该在未提交读模式下工作,因为它使数据看起来好像不存在事务,这很奇怪
不可重复读
鉴于上述情况,如果读取操作模式设置为“读取已提交”,则可能会发生不可重复读。此模式解决了脏读问题,因为只有提交的数据才会被读取。
可能的写入操作包括:
- 更新
- 插入
- 删除
非重复读(Non-Repeatable Read)是指在读取一组行数据后,再次执行同样的操作,返回相同的行数据集合(相同的键),但是非键数据已经发生了变化。
例如:
- 连接 A 可以从表中读取一组行数据。这些行数据是基于某些选择条件进行筛选的,例如
where子句。 - 连接 B 可能会更改此集合中的一个或多个行,以及其他行。
- 如果连接 A 重复执行相同的读取查询,则将返回相同的行数据集合,但是不属于“键”的数据可能已更改。
- “键”由
where或其他过滤器子句中的选择条件定义。
幻读
幻读是非重复读的扩展。插入或删除操作可能会更改返回的行数据集合。插入操作可能会向返回的行数据集合中添加新行。删除操作则可能相反,从返回的行数据集合中删除行。
总之:
- 连接A执行读操作
- 连接B执行插入或删除操作
- 连接A执行相同的读操作,返回不同的行集。新行可能出现,现有行可能消失。因此称为“幻象”读取。
隔离级别
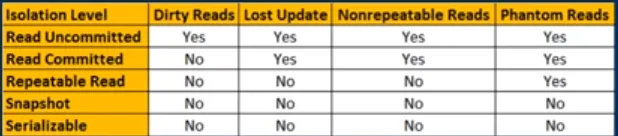
在我们理解潜在的不良行为的基础上,这就是隔离级别所做的:
- 未提交读取不会防止任何这些问题。然而,由于原子行操作仍然存在基本的保护级别。
- 读已提交只能防止脏读。
- 可重复读可以防止脏读和不可重复读,但无法防止幻象读。
- 串行化可以防止所有上述情况。
更高的隔离级别需要锁定数据库中更多的数据以防止并发访问。这可能是不理想的,因为如果DMBS在整个表上持有锁,则没有其他连接可以修改该数据。这可能导致需要访问数据库的其他进程停滞。
通常情况下,读已提交是最明智的选择。它确保您,数据库管理员,只看到已提交的数据(持久的数据,而不是短暂的数据),并且不会导致其他进程挂起。
参考文献
进一步阅读:
Geeks for Geeks 隔离级别。(请注意,其中一些信息没有任何意义,例如“读取已提交”(Read Committed)的解释,它声称这会导致提交任何未提交的数据。这是不正确的,也没有意义。未提交的数据只能通过显式提交操作进行提交。)
- FreelanceConsultant
1
请注意,在可重复读中,“repeatable”指的是一个元组,而不是整个表。在ANSI隔离级别中,可能会发生“幻读”异常,这意味着使用相同的where子句两次读取表可能会返回不同的结果集。从字面上看,它不是“可重复的”。
- 不辞长做岭南人
-1
我对初始接受的解决方案的观察。
在RR(默认mysql)下 - 如果一个tx是打开的并且已经触发了SELECT,那么另一个tx就不能删除任何属于先前READ结果集的行,直到先前的tx被提交(实际上,新tx中的删除语句将会挂起),但是下一个tx可以毫无问题地删除表中的所有行。顺便说一句,在先前的tx中进行的下一个READ操作仍将看到旧数据,直到它被提交。
- Sanjeev Dhiman
1
2你可能想把它放在评论区,这样回答者就会收到通知。这样他就能回应你的观察并进行必要的更正。 - RBT
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 24 如何在Django中设置“可重复读”事务?
- 3 提交读和可重复读示例比较
- 25 SQL Server:索引重建和索引重组有什么区别?
- 6 PostgreSQL如何实现可重复读隔离级别?
- 3 SQL Server 2012 - “可重复读”隔离级别是如何工作的?
- 53 在SQL Server中,'!='和' <>'有什么区别?
- 260 不可重复读取与幻读是数据库中的两个不同的问题。不可重复读取是指在同一个事务中,多次读取同一行数据时,得到的结果可能不一致。这是因为在事务执行期间,其他事务可能会对该行数据进行修改。而幻读则是指在同一个事务中,多次执行同一个查询时,得到的结果集可能不一致。这是因为在事务执行期间,其他事务可能会插入或删除符合查询条件的数据。这两个问题都是由于并发事务引起的,而解决这些问题的方法通常是使用事务隔离级别来控制并发访问。
- 52 可序列化和可重复读隔离级别有什么区别?
- 17 “可重复读”和“快照隔离”有什么区别?
- 10 MySQL中的读已提交与可重复读有何不同?