worldStates是一个Matlab MxNxL三维数组(张量),包含MxN网格的L种二进制值状态。
ps是与不同状态相关的概率的长度为L的列表。
函数[worldStates,ps] = StateMerge(worldStates,ps)应该删除重复的世界状态并将合并状态的概率相加到剩余的单个状态中。 重复状态是具有完全相同的二进制值配置的状态。
这是此功能的当前实现:
function [worldStates, ps] = StateMerge(worldStates, ps)
M = containers.Map;
for i = 1:length(ps)
s = worldStates(:,:,i);
s = mat2str(s);
if isKey(M, s)
M(s) = M(s) + ps(i);
else
M(s) = ps(i);
end
end
stringStates = keys(M);
n = length(stringStates);
sz = size(worldStates);
worldStates = zeros([sz(1:2), n]);
ps = zeros(1, 1, n);
for i = 1:n
worldStates(:,:,i) = eval(stringStates{i});
ps(i) = M(stringStates{i});
end
end
它使用Map来能够在O(L)时间内删除重复项,使用状态作为键和概率作为值。由于Matlab映射不允许将一般数据结构用作键,因此将状态转换为字符串表示形式以用作键,然后使用eval函数将其转换回数组。
事实证明,对于我需要处理多个状态(数量约为10^6)多次的需求(10^3),此代码速度太慢了。问题在于将矩阵转换为字符串需要大量时间,并且与状态大小缩放得不好。下面是一个小型25x25状态的示例:
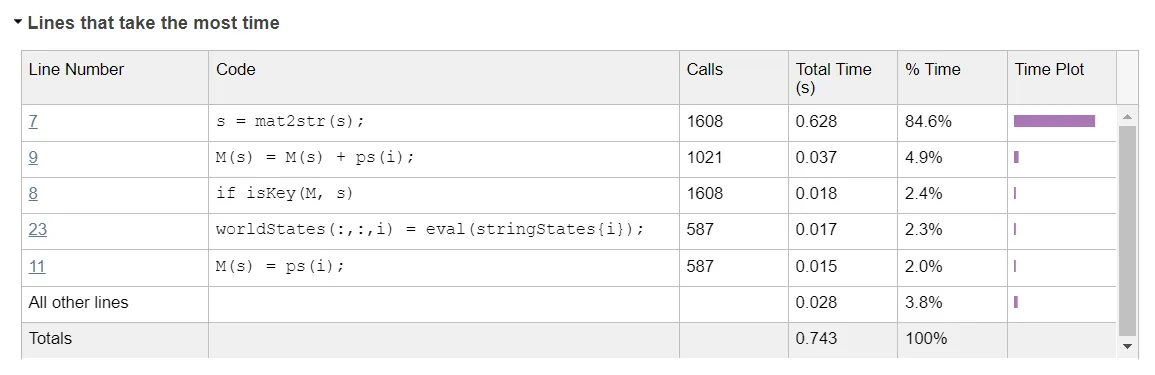
如何更有效地创建键?除了使用Map之外,是否有其他解决方案可以产生更好的结果?
编辑:按请求的可运行代码。此示例使合并变得不太可能:
worldStates = double(rand(25,25, 1000) > 0.5);
weights = rand(1,1, 1000);
ps = weights./sum(weights);
[worldStates, ps] = StateMerge(worldStates, ps);
在这个例子中会有很多合并操作:
worldStates = double(rand(25,25) > 0.5) .* ones(1,1,1000);
worldStates(1:2,1:2,:) = rand(2,2,1000) > 0.5;
weights = rand(1,1, 1000);
ps = weights./sum(weights);
[worldStates, ps] = StateMerge(worldStates, ps);
eval()函数,它会禁用JIT(即时编译),降低代码执行速度,并伴随着一系列问题。详见我的这个回答及其引用。请加上一个minimal, complete, and verifiable example (mcve),也就是可供我们运行的代码?对于纯数值矩阵使用eval和字符串并不高效。 - Adriaaneval的行可能很快,但其他函数可能会受到缺乏JIT的严重影响。 - Adriaanall(A(:,:,1)==A(:,:,2),'all')将比较两个矩阵是否完全相等(适用于二进制矩阵),然后通过简单的循环遍历所有可能性即可。可能可以通过利用'dim'参数或者更智能的检查来使其更加智能化(例如,~any()有可能在不相等时提前终止,而不是像all()那样一直执行到最后)。 - Adriaan