我有一张名为“Dummy”的表,其中包含“col1”和“col2”两列。
如何从(col1,col2)中找到唯一的对?例如,在上面的表格中,如何仅获取(a,b)或(b,a)作为输出,而不是同时获取(a,b)和(b,a)。
上述查询是错误的,因为它遗漏了(d,c)这一对。
如何从(col1,col2)中找到唯一的对?例如,在上面的表格中,如何仅获取(a,b)或(b,a)作为输出,而不是同时获取(a,b)和(b,a)。
select
distinct
col1
col2
from
dummy
where
dummy.col1 < dummy.col2
group by
col1,
col2;
上述查询是错误的,因为它遗漏了(d,c)这一对。
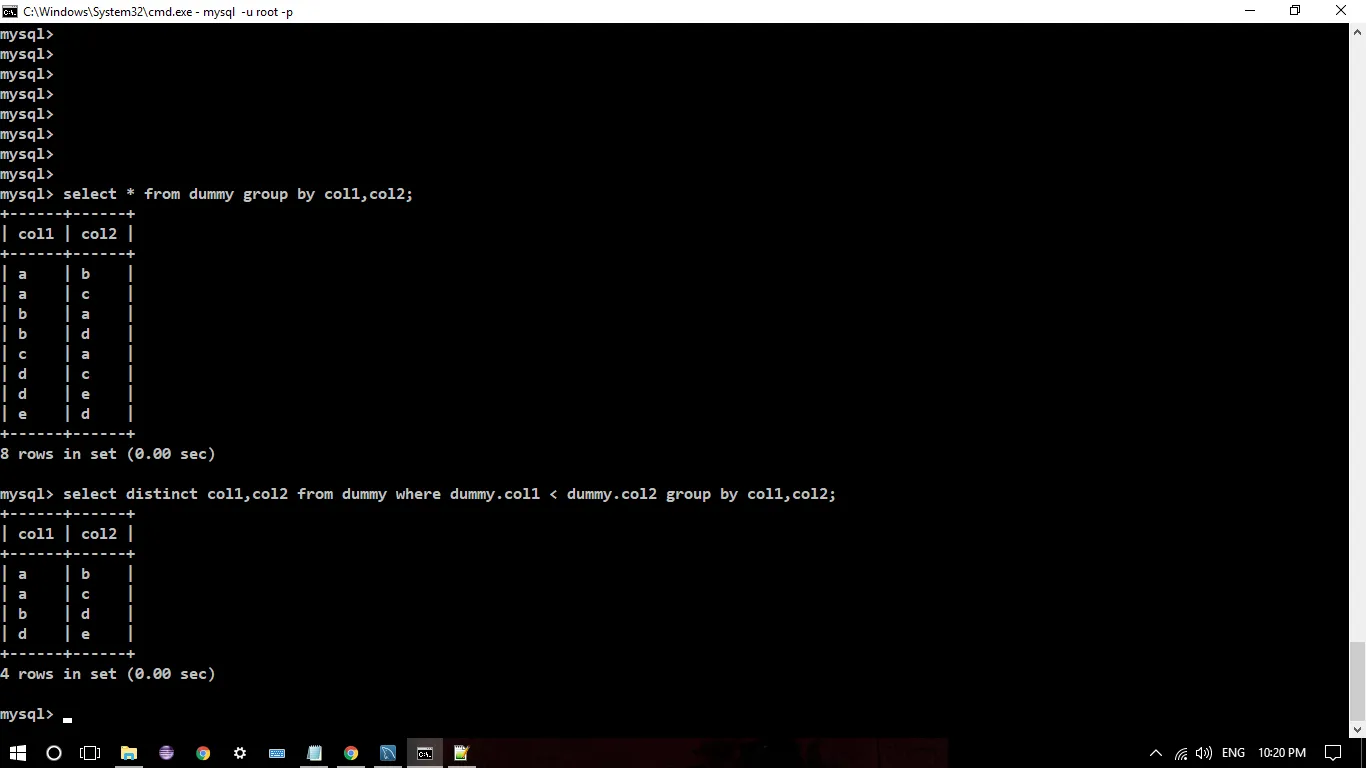
WHERE col1 <> col2,而不是WHERE col1 < col2。 - Daid,c还是c,d也可以? - dnoetha,d和d,a。 - lurker