这里有另外两种解决方案,它们似乎在quick-bench.com基准测试上表现更胜一筹。
其中一种解决方案经过测试,但使用clang编译后生成无分支代码:
int isleap3(int year) {
unsigned y = year + 16000;
return (y % 100) ? !(y % 4) : !(y % 16);
}
这个方法只使用了一次取模运算,没有测试,并且编译后只有两次乘法操作:
static unsigned char const leaptest[400] = {
1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
};
int isleap4(int year) {
unsigned y = year + 16000;
return leaptest[y % 400];
}
clang 64位汇编:
isleap3:
add edi, 16000
imul eax, edi, -1030792151
ror eax, 2
cmp eax, 42949673
mov eax, 15
mov ecx, 3
cmovb ecx, eax
xor eax, eax
test ecx, edi
sete al
ret
isleap4:
add edi, 16000
imul rax, rdi, 1374389535
shr rax, 39
imul eax, eax, 400
sub edi, eax
movzx eax, byte ptr [rdi + leaptest]
ret
leaptest:
.asciz "\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000"
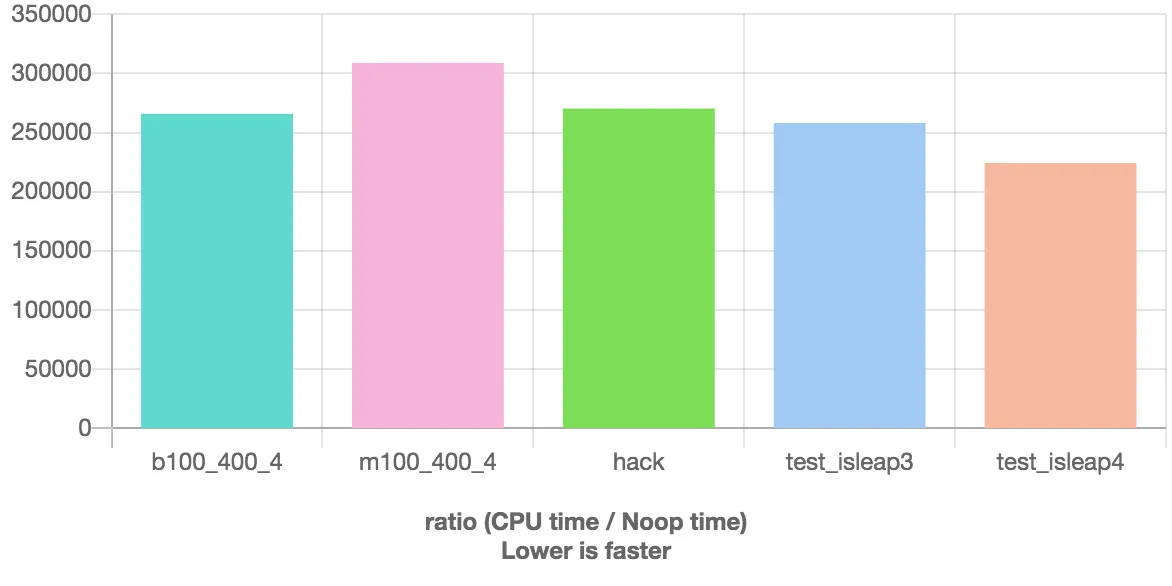
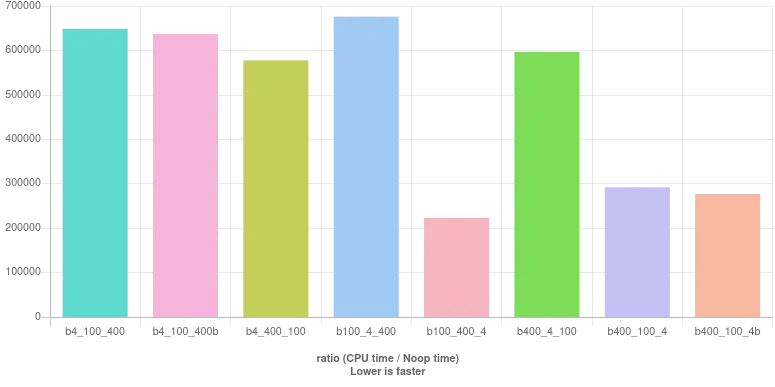
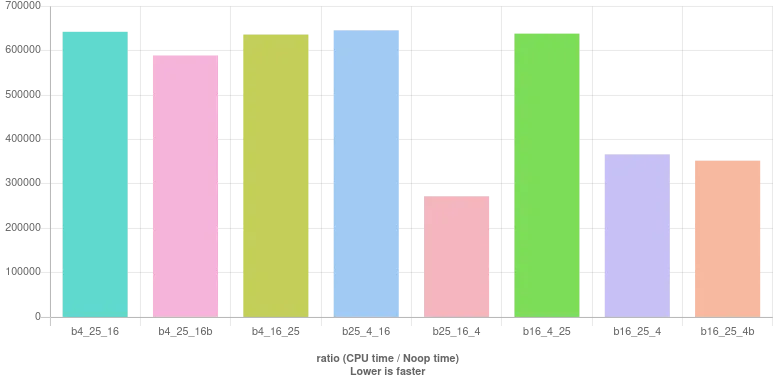
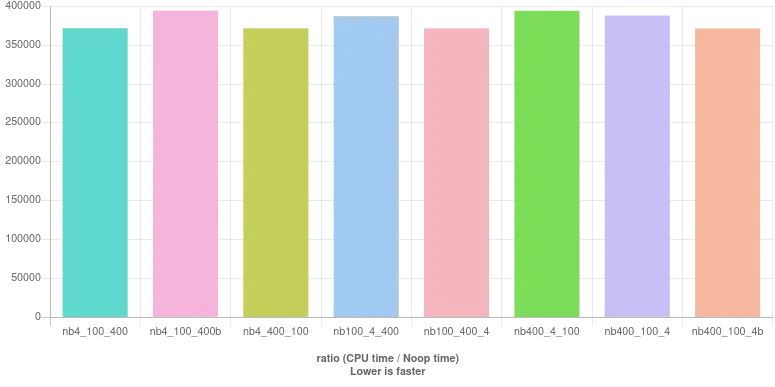
这里是基准测试结果:
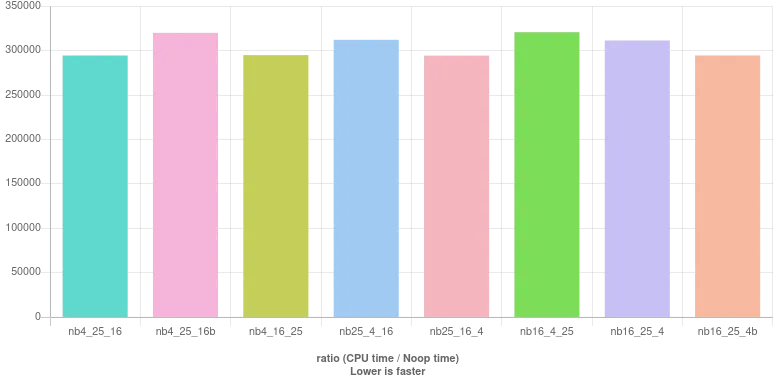
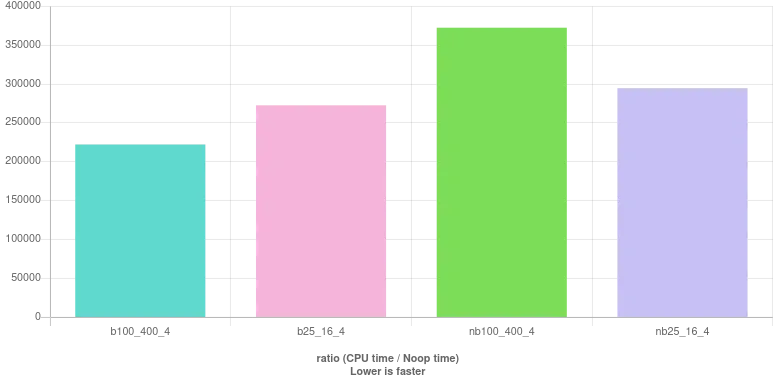
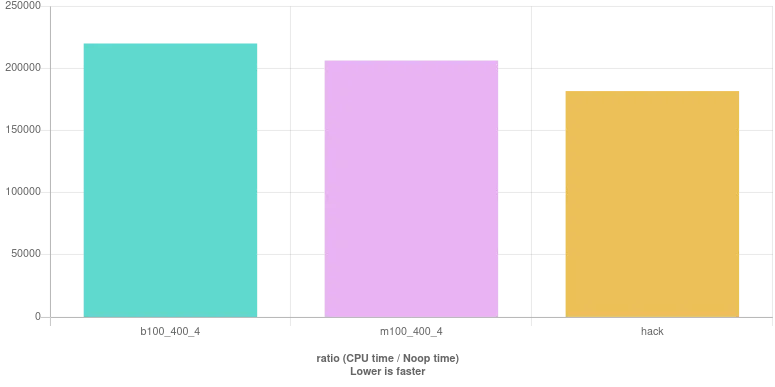
yearr是一个查找闰年的函数的不好的名称。在C中,main返回int而不是void。 - Alok Singhal(year % 4 == 0 && year % 100 != 0) || year % 400 == 0- Susam Pal