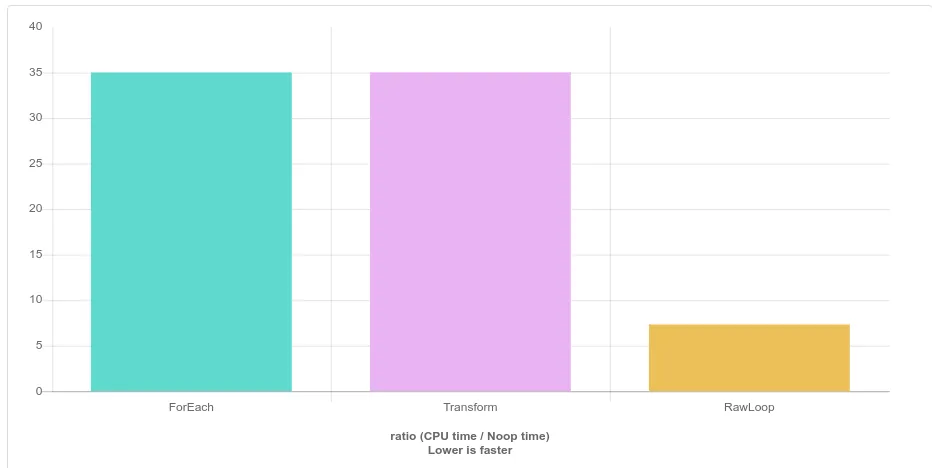
在这个例子中,clang向量化了索引,但是(错误地)未能向量化迭代。总结结果,使用原始循环与使用std::transform或std::for_each没有区别。然而,在使用索引和迭代时存在差异,在这个特定问题的情况下,clang在优化索引方面比优化迭代更好,因为索引被向量化了。std::transform和std::for_each使用迭代,因此它们在clang编译下变得更慢。什么是索引和迭代之间的区别?-索引是当您使用整数索引到数组中时,-迭代是当您从begin()到end()增加指针时。让我们使用索引和迭代编写原始循环,并比较迭代(使用原始循环)与索引的性能。
// Indexing
for(int i = 0; i < a.size(); i++) {
a[i] = !a[i];
}
bool* begin = a.data();
bool* end = begin + a.size();
for(; begin != end; ++begin) {
*begin = !*begin;
}
使用索引的示例进行了更好的优化,并在使用clang编译时运行速度快4-5倍。
为了证明这一点,让我们添加两个额外的测试,都使用原始循环。一个将使用迭代器,另一个将使用原始指针。
static void RawLoopIt(benchmark::State& state) {
std::array<bool, 16> a;
std::fill(a.begin(), a.end(), true);
for(auto _ : state) {
auto scan = a.begin();
auto end = a.end();
for (; scan != end; ++scan) {
*scan = !*scan;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(RawLoopIt);
static void RawLoopPtr(benchmark::State& state) {
std::array<bool, 16> a;
std::fill(a.begin(), a.end(), true);
for(auto _ : state) {
bool* scan = a.data();
bool* end = scan + a.size();
for (; scan != end; ++scan) {
*scan = !*scan;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(RawLoopPtr);
当使用指针或迭代器从
begin到
end时,这些函数在性能上与使用
std::for_each或
std::transform相同。
Clang Quick-bench结果: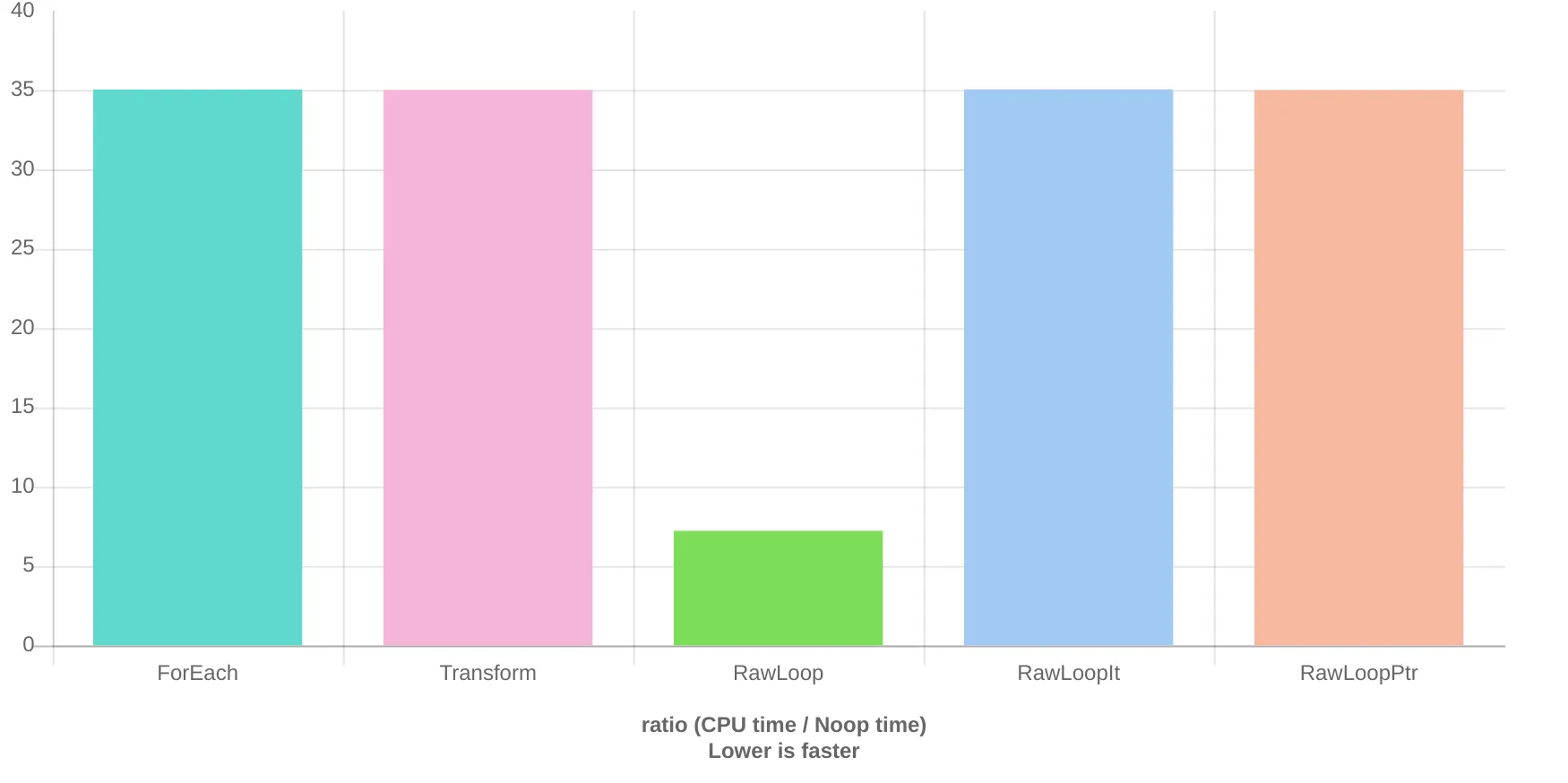
这在本地运行clang基准测试时得到了证实。
me@K2SO:~/projects/scratch$ clang++ -O3 bench.cpp -lbenchmark -pthread -o clang-bench
me@K2SO:~/projects/scratch$ ./clang-bench
2019-07-05 16:13:27
Running ./clang-bench
Run on (8 X 4000 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 8192K (x1)
Load Average: 0.44, 0.55, 0.59
-----------------------------------------------------
Benchmark Time CPU Iterations
-----------------------------------------------------
ForEach 8.32 ns 8.32 ns 83327615
Transform 8.29 ns 8.28 ns 82536410
RawLoop 1.92 ns 1.92 ns 361745495
RawLoopIt 8.31 ns 8.31 ns 81848945
RawLoopPtr 8.28 ns 8.28 ns 82504276
GCC没有这个问题。
就本例而言,索引或迭代之间并没有根本的区别。它们都对数组应用相同的转换,编译器应该能够将它们编译成相同的代码。
事实上,GCC能够做到这一点,所有方法都比在clang下编译的相应版本运行得更快。
GCC Quick-bench结果:
GCC本地结果:
2019-07-05 16:13:35
Running ./gcc-bench
Run on (8 X 4000 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 8192K (x1)
Load Average: 0.52, 0.57, 0.60
Benchmark Time CPU Iterations
ForEach 1.43 ns 1.43 ns 484760981
Transform 1.44 ns 1.44 ns 485788409
RawLoop 1.43 ns 1.43 ns 484973417
RawLoopIt 1.44 ns 1.44 ns 482685685
RawLoopPtr 1.44 ns 1.44 ns 483736235
索引比迭代快的原因是clang进行了向量化处理,本质上并非如此。
实际上,在底层中,既不是迭代也不是索引的运行。相反,gcc和clang通过将数组视为两个64位整数,并对它们进行按位异或运算来向量化操作。我们可以从用于翻转位的汇编代码中看到这一点:
最初的回答: Is indexing actually faster than iterating? No. Indexing is faster because clang vectorizes it.
在幕后,实际上并没有进行迭代或索引。而是通过gcc和clang将数组视为两个64位整数,并使用位异或对其进行向量化操作。我们可以从用于翻转位的汇编中看到这一点。
movabs $0x101010101010101,%rax
nopw %cs:0x0(%rax,%rax,1)
xor %rax,(%rsp)
xor %rax,0x8(%rsp)
sub $0x1,%rbx
当使用clang编译时,迭代速度较慢,因为由于某种原因,当使用迭代时,clang无法对操作进行矢量化。这是clang的一个缺陷,只适用于此问题。随着clang的改进,这种差异应该会消失,并且现在不是我担心的事情。
不要进行微观优化。让编译器处理,如果必要,测试gcc或clang是否针对您的特定用例生成更快的代码。两者都不是所有情况下都更好。例如,clang在某些数学运算中更擅长进行矢量化。