我正在训练一个多标签分类模型来检测服装的属性。我在Keras中使用迁移学习,重新训练vgg-19模型的最后几层。
总属性数为1000,其中大约99%是0。像准确率、精度、召回率等指标都无法正确评估,因为模型可以预测全部为零的情况下仍然获得非常高的分数。在损失函数方面,二元交叉熵、汉明损失等都没有效果。
我正在使用深度时尚数据集。
那么,我应该使用哪些指标和损失函数来正确评估我的模型呢?
我正在训练一个多标签分类模型来检测服装的属性。我在Keras中使用迁移学习,重新训练vgg-19模型的最后几层。
总属性数为1000,其中大约99%是0。像准确率、精度、召回率等指标都无法正确评估,因为模型可以预测全部为零的情况下仍然获得非常高的分数。在损失函数方面,二元交叉熵、汉明损失等都没有效果。
我正在使用深度时尚数据集。
那么,我应该使用哪些指标和损失函数来正确评估我的模型呢?
哈桑提出的建议是不正确的 - 分类交叉熵损失或Softmax损失是一个Softmax激活和一个交叉熵损失。如果我们使用这个损失函数,我们将训练卷积神经网络为每张图像输出C类别的概率,它被用于多类别分类。
你所需的是多标签分类,因此你需要使用二元交叉熵损失或Sigmoid交叉熵损失。它是一个Sigmoid激活和一个交叉熵损失。与Softmax损失不同,它对每个向量组件(类)都是独立的,意味着为每个CNN输出向量组件计算的损失值不受其他组件值的影响。这就是为什么它被用于多标签分类的原因,其中一个元素属于某个类别的认识不应影响到决定另一个类别的判断。
现在对于处理类别不平衡问题,可以使用加权Sigmoid交叉熵损失。因此,你将基于正例的数量/比率来对错误预测进行惩罚。
tf.nn.weighted_cross_entropy_with_logits。
它不仅适用于多标签分类,还有一个pos_weight可以更加重视你期望的正类。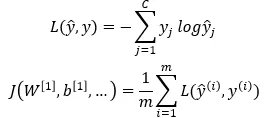
二元交叉熵:
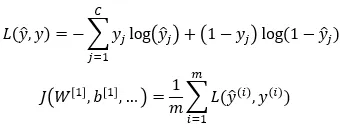
C 是类别的数量,m 是当前小批量中的示例数。 L 是损失函数,J 是代价函数。 您也可以在 这里 看到。
在损失函数中,您正在迭代不同的类别。 在代价函数中,您正在迭代当前小批量中的示例。
Steve
我曾经处于和你类似的情况。
你可以在输出层使用softmax激活函数,并结合分类交叉熵检查其他指标,例如精度、召回率和F1分数,你可以按以下方式使用sklearn库:
from sklearn.metrics import classification_report
y_pred = model.predict(x_test, batch_size=64, verbose=1)
y_pred_bool = np.argmax(y_pred, axis=1)
print(classification_report(y_test, y_pred_bool))
关于培训阶段,据我所知有以下准确度指标
model.compile(loss='categorical_crossentropy'
, metrics=['acc'], optimizer='adam')
hist = model.fit(x_train, y_train, batch_size=24, epochs=1000, verbose=2,
callbacks=[checkpoint],
validation_data=(x_valid, y_valid)
)
# Plot training & validation accuracy values
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()