这里有一个不错的例子。我做了 4x4 的示例,方便查看,但是可以通过 n 进行调整。它也是完全矢量化的,速度应该很快。
n = 4
mat = matrix(1:n^2, nrow = n)
mat.pad = rbind(NA, cbind(NA, mat, NA), NA)
通过填充矩阵,邻居就是大小为n乘n的子矩阵,可以在周围移动。使用罗盘方向作为标签:
ind = 2:(n + 1)
neigh = rbind(N = as.vector(mat.pad[ind - 1, ind ]),
NE = as.vector(mat.pad[ind - 1, ind + 1]),
E = as.vector(mat.pad[ind , ind + 1]),
SE = as.vector(mat.pad[ind + 1, ind + 1]),
S = as.vector(mat.pad[ind + 1, ind ]),
SW = as.vector(mat.pad[ind + 1, ind - 1]),
W = as.vector(mat.pad[ind , ind - 1]),
NW = as.vector(mat.pad[ind - 1, ind - 1]))
mat
neigh[, 1:6]
因此,您可以看到第一个元素
mat [1,1],从北部开始顺时针移动,邻居是
neigh的第一列。下一个元素是
mat [2,1],以此类推沿着
mat的列向下移动。(您还可以与@mrip的答案进行比较,看到我们的列具有相同的元素,只是顺序不同。)
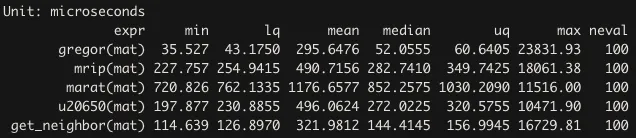
基准测试
小矩阵
mat = matrix(1:16, nrow = 4)
mbm(gregor(mat), mrip(mat), marat(mat), u20650(mat), times = 100)
在一个较大的矩阵中,我不得不删除user20650的函数,因为它尝试分配一个232.8 Gb的向量,并且在等待约10分钟后,我也删除了Marat的答案。
mat = matrix(1:500^2, nrow = 500)
mbm(gregor(mat), mrip(mat), times = 100)
所以,无论何时时间都很重要,@mrip的解决方案都是最快的。
使用的函数:
gregor = function(mat) {
n = nrow(mat)
mat.pad = rbind(NA, cbind(NA, mat, NA), NA)
ind = 2:(n + 1)
neigh = rbind(N = as.vector(mat.pad[ind - 1, ind ]),
NE = as.vector(mat.pad[ind - 1, ind + 1]),
E = as.vector(mat.pad[ind , ind + 1]),
SE = as.vector(mat.pad[ind + 1, ind + 1]),
S = as.vector(mat.pad[ind + 1, ind ]),
SW = as.vector(mat.pad[ind + 1, ind - 1]),
W = as.vector(mat.pad[ind , ind - 1]),
NW = as.vector(mat.pad[ind - 1, ind - 1]))
return(neigh)
}
mrip = function(mat) {
m2<-cbind(NA,rbind(NA,mat,NA),NA)
addresses <- expand.grid(x = 1:4, y = 1:4)
ret <- c()
for(i in 1:-1)
for(j in 1:-1)
if(i!=0 || j !=0)
ret <- rbind(ret,m2[addresses$x+i+1+nrow(m2)*(addresses$y+j)])
return(ret)
}
get.neighbors <- function(rw, z, mat) {
z2 <- t(z + unlist(rw))
b.good <- rowSums(z2 > 0)==2 & z2[,1] <= nrow(mat) & z2[,2] <= ncol(mat)
mat[z2[b.good,]]
}
marat = function(mat) {
n.row = n.col = nrow(mat)
addresses <- expand.grid(x = 1:n.row, y = 1:n.col)
z <- rbind(c(-1,0,1,-1,1,-1,0,1), c(-1,-1,-1,0,0,1,1,1))
apply(addresses, 1,
get.neighbors, z = z, mat = mat)
}
u20650 = function(mat) {
w <- which(mat==mat, arr.ind=TRUE)
d <- as.matrix(dist(w, "maximum", diag=TRUE, upper=TRUE))
a <- apply(d, 1, function(i) mat[i == 1] )
names(a) <- mat
return(a)
}

NA,或者可能是其他一些操作。 - Gregor ThomasNA,你可以在矩阵中填充NA(使其成为12x12,第一行和最后一行以及第一列和最后一列都是NA),这样你就可以只查看“中间”的所有邻居,从而避免在代码中进行大量的特殊处理。 - Gregor Thomas