我遇到了下面的问题。
注:该内容为HTML标记,无需翻译。
You are given the root of a binary tree with n nodes.
Each node is uniquely assigned a value from 1 to n.
You are also given an integer startValue representing
the value of the start node s,
and a different integer destValue representing
the value of the destination node t.
Find the shortest path starting from node s and ending at node t.
Generate step-by-step directions of such path as a string consisting of only the
uppercase letters 'L', 'R', and 'U'. Each letter indicates a specific direction:
'L' means to go from a node to its left child node.
'R' means to go from a node to its right child node.
'U' means to go from a node to its parent node.
Return the step-by-step directions of the shortest path from node s to node t
示例1:
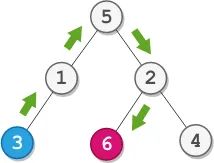
Input: root = [5,1,2,3,null,6,4], startValue = 3, destValue = 6
Output: "UURL"
Explanation: The shortest path is: 3 → 1 → 5 → 2 → 6.
示例 2:
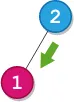
注:该内容为HTML标记,无需翻译。
Input: root = [2,1], startValue = 2, destValue = 1
Output: "L"
Explanation: The shortest path is: 2 → 1.
我通过找到最近公共祖先,然后进行深度优先搜索来查找元素,创建了这个解决方案:
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):
def getDirections(self, root, startValue, destValue):
"""
:type root: Optional[TreeNode]
:type startValue: int
:type destValue: int
:rtype: str
"""
def lca(root):
if root == None or root.val == startValue or root.val == destValue:
return root
left = lca(root.left)
right = lca(root.right)
if left and right:
return root
return left or right
def dfs(root, value, path):
if root == None:
return ""
if root.val == value:
return path
return dfs(root.left, value, path + "L") + dfs(root.right, value, path + "R")
root = lca(root)
return "U"*len(dfs(root, startValue, "")) + dfs(root, destValue, "")
这个解决方案表现不错,但对于非常大的输入,它会抛出“内存限制超出”错误。有人能告诉我如何优化解决方案,或者可能是我做了什么导致这个错误吗?
.left等属性,因此该列表显然只是评判代码的输入,而不是函数获取的root参数。 (文档字符串还指出其类型为Optional [TreeNode]。) - Kelly Bundy