我刚刚看到了你有关4x4矩阵的评论。在现代x86 CPU上,一个大小为4x4的int数组可以适配于单个缓存行(缓存行大小为64B)。在这种情况下,您需要编译器生成类似以下的代码:
## matrix address in [rdi]
movups xmm0, [rdi]
movups xmm1, [rdi+16]
movups xmm2, [rdi+32]
movups xmm3, [rdi+48]
movups [rdi], xmm1 ; doing all the stores after all the loads avoids any possible false dependency
movups [rdi+16], xmm2
movups [rdi+32], xmm3
movups [rdi+48], xmm0
或许可以减少AVX 256b的加载/存储,但不对齐的AVX可能会更差。如果数组是64B对齐的,则所需的所有加载/存储都不会跨越缓存行边界。因此,需要2个
vmovups ymm加载,一个
vmovups ymm存储,一个
vmovups xmm存储(到末尾),以及一个
vextractf128存储(到开头)。
如果幸运的话,当函数内联到具有编译时常量值为
4的调用者中时,John的memcpy将优化为以下内容。
对于小型数组,问题不在于缓存未命中,而在于如何使整个复制过程的开销最小化。我下面关于引入间接级别的想法不是一个好主意,因为加载所有数据并将其重新存储非常便宜。
对于大矩阵:
如果您在矩阵末尾留出另一行的空间,您可以将第一行复制到此额外空间,并传递指向原来第二行的指针。
这使您可以暂时以不同的方式查看矩阵,但这不是可重复的过程。
如果您有一个大缓冲区,您可以继续通过这种方式旋转矩阵行,直到到达保留空间的末尾并必须将数组复制回缓冲区的顶部。这最小化了复制开销,但确实意味着您正在触及一些新的内存。
如果行复制开销很大,引入一层间接可能是个好主意。根据代码的访问模式,在你洗牌行之后使用它的代码可能会更糟。这可能是指针数组而不是普通的二维数组的用例。
您可以并且应该使用一次大的分配来分配矩阵的存储空间,而不是单独分配每一行。 C++的vector不是理想的选择。初始化
int *rows[M]只需要一个
&A[i][0]的循环,所以这只是数学问题,而不是多次加载或分配。
通过这个间接表访问数组用指针追踪替换
N+j数学:先加载
rows[i],然后使用
j索引。
当您不需要数组的洗牌视图时,您可以直接访问它,但如果您想对数组进行永久洗牌,则所有用户都必须始终通过间接层进行访问。
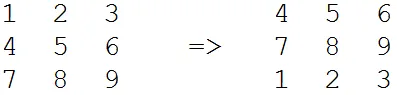
temprow在编译时能够正常大小,如果您需要多次执行此操作,则可能会有所帮助(但是否应该多次执行此操作是另一回事!)。 - John Zwinckmov指令的memcpy/memmove,不像gcc 5.3版本(其中仍然调用memmove)。 - Peter Cordes