在我尝试了许多不同的JVM GC设置并进行了大量测试后,我现在正在测试G1GC JVM GC。除此之外,我还使用性能监视器收集数据,并且唯一运行的应用程序(除系统服务之外)是GlassFish服务器和我的应用程序。我在性能监视器日志中没有发现任何奇怪的情况(CPU使用率约为5-10%,当GC发生时会略微增加,内存使用率约为60% ...)。现在是第五天的测试,我注意到以下情况:
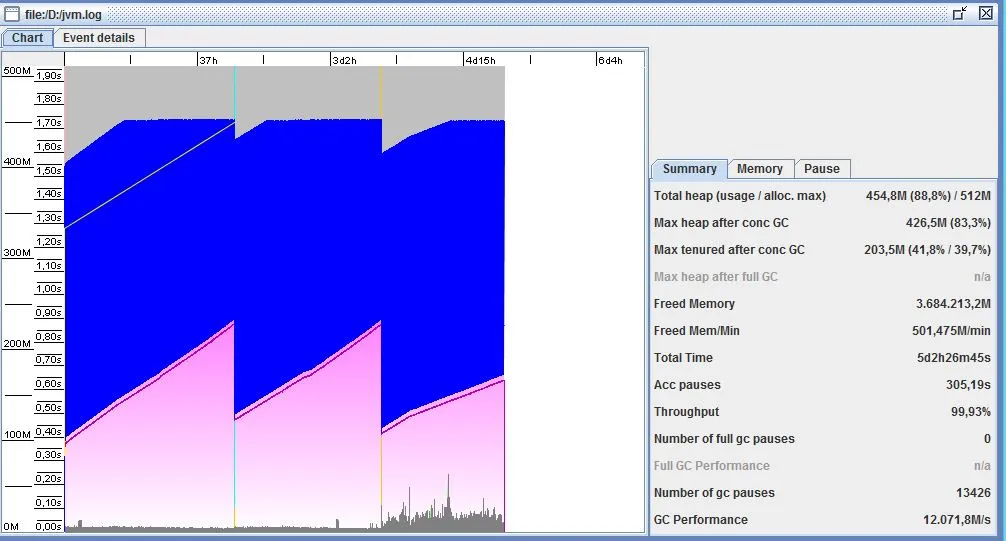
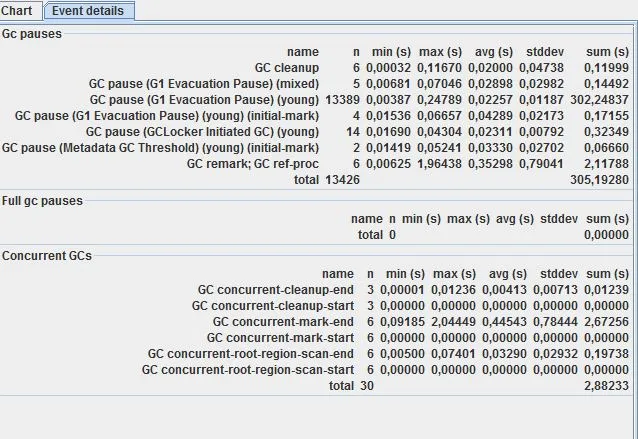
编辑:这里是完整的GC日志文件,已导入GCViewer以及来自GCViewer的事件详细信息统计:
第三个主要GC的日志:
2015-06-08T08:09:13.123+0200: 572815.533: [GC concurrent-root-region-scan-start]
2015-06-08T08:09:13.139+0200: 572815.560: [GC concurrent-root-region-scan-end, 0.0271771 secs]
2015-06-08T08:09:13.139+0200: 572815.560: [GC concurrent-mark-start]
2015-06-08T08:09:16.302+0200: 572818.721: [GC concurrent-mark-end, 3.1612900 secs]
2015-06-08T08:09:16.318+0200: 572818.729: [GC remark 572818.729: [Finalize Marking, 0.0002590 secs] 572818.729: [GC ref-proc, 0.4479462 secs] 572819.177: [Unloading, 3.2004912 secs], 3.6499382 secs]
[Times: user=0.20 sys=0.08, real=3.64 secs]
再次提醒,实时响应时间远高于用户+系统时间,卸载阶段需要超过3秒的时间。
-XX:+PrintGCDetails进行记录。 - the8472