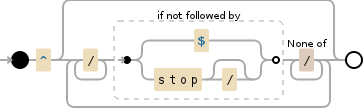
我已经进行了一段时间的调研,但没有找到匹配以下模式的线索(虽然我对正则表达式非常陌生),它看起来像
/abc/foo/bar(/*)
或者
/abc/foo/bar/stop
我希望将上述字符串匹配并捕获为/abc/foo/bar。现在,"/stop"是一个可选的字符串,可能附加在模式的末尾。目标是在忽略“stop”(如果存在,并且如果“stop”出现多次,则停止在第一个“stop”)的情况下获取所需的捕获,同时允许在中间使用尽可能多的斜杠,除了行末的斜杠。
如果我只是简单地这样做:
^(/.*[^/])/*$
我需要一份能够涵盖所有斜杠的贪婪正则表达式,直到我去除可能的最后一个斜杠。但是为了接受第二种情况,即我有一个可选的"/stop",我需要以非贪婪的方式匹配,直到找到第一个可能的"/stop"并在那里停止。
我该如何制作一个单一的正则表达式来匹配这两种情况?
编辑:不确定我的先前示例是否足够清晰。请尝试给出更多,例如我想在以下所有字符串中匹配并捕获"/abc/foo/bar":
/abc/foo/bar
/abc/foo/bar/
/abc/foo/bar///
/abc/foo/bar/stop
/abc/foo/bar/stop/foo/bar/stop/stop
/abc/foo/bar//stop
虽然它不会匹配以下任何一个:
/abc/foo/bar/sto (will match the whole "/abc/foo/bar/sto" instead)
/abc/foo/bar/abc/foo/bar (it will catch "/abc/foo/bar/abc/foo/bar" instead)
如果这样讲得够清楚,请告诉我。谢谢!