我正在尝试构建一个流水线,首先对我的训练数据进行随机主成分分析(RandomizedPCA),然后拟合一个岭回归模型。以下是我的代码:
我知道关于
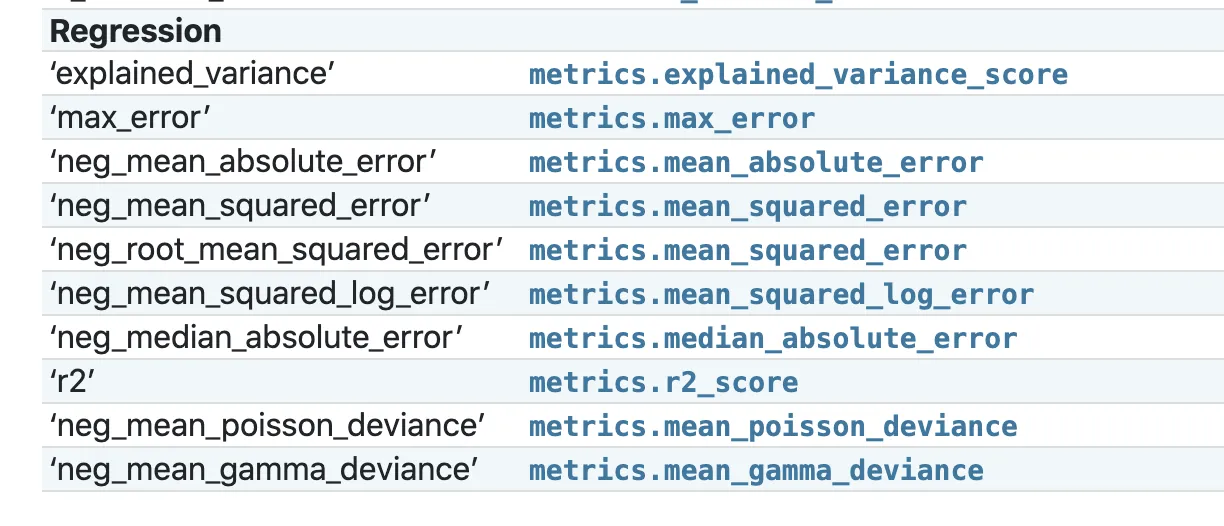
我希望网格搜索CV能报告RMSE误差,但是在sklearn中似乎不支持这个功能,所以我只能使用MSE。然而,它报告的分数是负数。
显然,对于均方误差来说这是不可能的 - 我在这里做错了什么?
pca = RandomizedPCA(1000, whiten=True)
rgn = Ridge()
pca_ridge = Pipeline([('pca', pca),
('ridge', rgn)])
parameters = {'ridge__alpha': 10 ** np.linspace(-5, -2, 3)}
grid_search = GridSearchCV(pca_ridge, parameters, cv=2, n_jobs=1, scoring='mean_squared_error')
grid_search.fit(train_x, train_y[:, 1:])
我知道关于
RidgeCV函数,但我想尝试一下Pipeline和GridSearch CV。我希望网格搜索CV能报告RMSE误差,但是在sklearn中似乎不支持这个功能,所以我只能使用MSE。然而,它报告的分数是负数。
In [41]: grid_search.grid_scores_
Out[41]:
[mean: -0.02665, std: 0.00007, params: {'ridge__alpha': 1.0000000000000001e-05},
mean: -0.02658, std: 0.00009, params: {'ridge__alpha': 0.031622776601683791},
mean: -0.02626, std: 0.00008, params: {'ridge__alpha': 100.0}]
显然,对于均方误差来说这是不可能的 - 我在这里做错了什么?