我正在尝试使用RMarkdown pdf撰写论文。但我不知道如何使用特殊字符,例如“İ, ı, ğ, ü, ö”。这些字符在土耳其语中很常见。我可以很容易地在Latex中使用它们,例如\u{g} - ğ,\c{c} - ç,\"{u} - ü,{\i} - ı等。
请问我该如何在RMarkdown中做到同样的效果?
另外,您知道哪里可以找到一些RMarkdown论文或书籍模板吗?
我正在尝试使用RMarkdown pdf撰写论文。但我不知道如何使用特殊字符,例如“İ, ı, ğ, ü, ö”。这些字符在土耳其语中很常见。我可以很容易地在Latex中使用它们,例如\u{g} - ğ,\c{c} - ç,\"{u} - ü,{\i} - ı等。
请问我该如何在RMarkdown中做到同样的效果?
另外,您知道哪里可以找到一些RMarkdown论文或书籍模板吗?
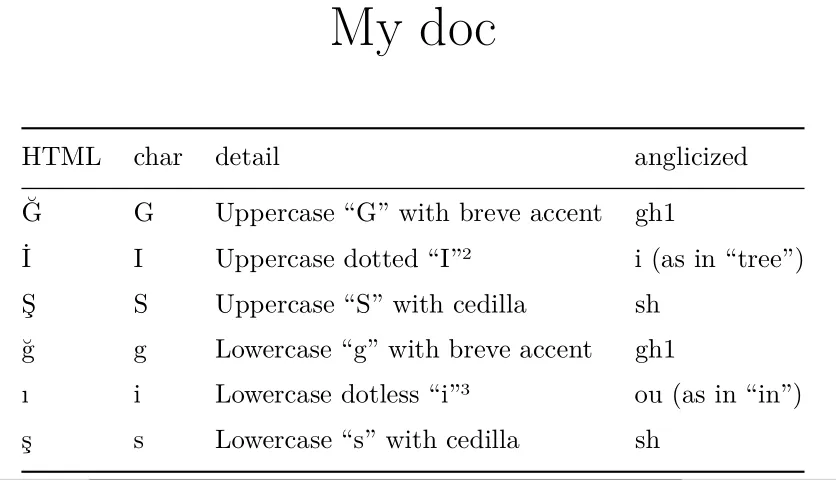
土耳其字符的HTML代码将会有效(来自维基百科的示例):
---
title: "My doc"
output: pdf_document
---
HTML char detail anglicized
------- -- ------------------------------ ---
Ğ Ğ Uppercase "G" with breve accent gh1
İ İ Uppercase dotted "I"² i (as in "tree")
Ş Ş Uppercase "S" with cedilla sh
ğ ğ Lowercase "g" with breve accent gh1
ı ı Lowercase dotless "i"³ ou (as in "in")
ş ş Lowercase "s" with cedilla sh
------- -- ------------------------------- --
将PDF呈现为如下所示:
有关书籍模板,请查看pandoc电子书,gitbook 和 bookdown
我最初建议的这个xelatex选项不会适用于土耳其字符:
xelatex引擎是推荐使用的类型。然后,您可以通过mainfont参数访问系统字体:
---
title: "My doc"
output:
pdf_document:
latex_engine: xelatex
mainfont: "name of your system font that has all those characters"
---
PDF output will be in the font you specify.
Just type as normal with no special codes.
我猜这个问题本身已经过时了。截至目前(rmarkdown V1.4 / knitr V1.15.1), knitr自动按照这个问题的建议包含内容。
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
在LaTeX输出的导言部分(注意:这意味着您的文档编辑器必须使用UTF-8编码,但例如RStudio默认使用UTF-8编码),
然后这将按预期工作:
---
title: "Test"
output: pdf_document
---
Here are some special characters: İ ı Ş Ğ ş ğ ö ü
这并不是万能药,因为许多脚本仍需要更多的调整(我尝试过韩语、中文和日语)。如果您需要更多的多样化字体,请参见 此处,了解如何加强导言部分。
rmarkdown使用LaTeX创建PDF文档,因此您应该可以直接使用LaTeX标记。以下是一个示例:
---
title: "Test"
output: pdf_document
---
This is a special character: \u{g}.
http://www.starr.net/is/type/htmlcodes.html
请确保包含;。可能已经有点晚了,但我想在现有的惊人而直接的答案中添加一些东西。这个答案不仅适用于pdf_documents,还适用于html_和word_documents。
解决方案:使用
capture.output()和cat()示例:考虑写入ñ。快速查看https://www.compart.com/en/unicode/U+00F1,给出了ñ的U+00F1代码。在R中,这是\u00f1。一个MWE如下所示。
---
title: "Minimum Working Example"
author: "Mr. John Ate`r capture.output(cat('\u00f1'))`o"
output:
pdf_document: default
word_document: default
html_document: default
---
## Some Example of Printing `r capture.output(cat('\u00f1'))`
This is an inline output of `r capture.output(cat('\u00f1'))`.
简化:每次使用capture.output(cat())都很繁琐,所以我们可以定义一个自定义函数,比如说
diac <- function(x) {
capture.output(cat(x))
}
然后如下内联使用:`r diac('\u00f1')`。