- 栈和堆是什么?
- 它们在计算机内存中的物理位置在哪里?
- 它们在多大程度上受操作系统或语言运行时的控制?
- 它们的作用范围是什么?
- 是什么决定它们的大小?
- 是什么使它们更快?
栈和堆是什么?它们分别位于哪里?
9349
- matt
7
32个回答
124
堆栈是一段内存,可以通过几个关键的汇编语言指令进行操作,例如'pop'(从栈中删除并返回值)和'push'(将值推到栈上),还有call(调用子程序-这会将返回地址压入栈上)和return(从子程序返回-这会弹出地址并跳转到它)。它是位于栈指针寄存器下方的内存区域,可以根据需要设置。堆栈也用于向子例程传递参数,并在调用子例程之前保留寄存器中的值。
堆是操作系统通过类似于malloc的系统调用提供给应用程序的一部分内存。在现代操作系统中,这段内存是一组只有调用进程才能访问的页面。
堆栈的大小在运行时确定,在程序启动后通常不会增长。在C程序中,堆栈的大小需要足够大,以容纳每个函数内声明的变量。堆将根据需要动态增长,但是操作系统最终决定(通常会比malloc请求的值多增加堆,以便将来的某些malloc不需要返回内核获取更多内存。此行为通常是可自定义的)
由于在启动程序之前已经分配了堆栈,因此您永远不需要在使用堆栈之前malloc,因此这是一个小优势。在实践中,很难预测现代操作系统中虚拟内存子系统中什么会快,什么会慢,因为页面的实现方式以及它们存储的位置是实现细节。
- dannyp
1
2在这里值得一提的是,英特尔对栈访问进行了大量优化,特别是预测从函数返回的位置等方面。 - Tom Leys
122
我认为许多其他人已经就这个问题给出了大多数正确的答案。
然而,一个被忽略的细节是,“堆(heap)”实际上可能应该被称为“自由存储(free store)”。这种区别的原因是最初的free store是用一种名为“二项堆(binomial heap)”的数据结构实现的。因此,从早期的malloc()/free()分配是从堆中分配的。但是,在今天,大多数自由存储都是使用非常复杂的数据结构实现的,而不是二项堆。
- Heath
2
8另一个小问题——大多数答案(轻微地)暗示
C 语言需要使用“堆栈”。虽然这是实现 C99 6.2.4 自动存储期对象(变量)的(远远)主要范例,但这是一个常见的误解。实际上,“堆栈”这个词甚至没有出现在 C99 语言标准中:http://www.open-std.org/JTC1/SC22/WG14/www/docs/n1256.pdf - johne[@Heath] 我对你的回答有一点小评论。看看这个问题的被接受的答案(https://dev59.com/f3VC5IYBdhLWcg3wnCaA)。它说,**自由存储区**很可能与**堆**相同,但不一定是。 - OmarOthman
97
您可以使用栈来进行一些有趣的操作。例如,您可以使用像alloca这样的函数(假设您能够通过关于其使用的大量警告),它是一种特别使用栈而非堆的内存分配方式。
话虽如此,基于栈的内存误操作是我经历过的最糟糕的问题之一。如果您使用堆内存,并超出了已分配块的边界,您很可能会触发段错误。(不是 100%:您的块可能与您先前分配的另一个块巧合地相邻)。但由于在栈上创建的变量总是彼此相邻的,因此越界写入可能会更改另一个变量的值。我已经学会了,每当感觉我的程序停止遵守逻辑规则时,那就可能是缓冲区溢出。
话虽如此,基于栈的内存误操作是我经历过的最糟糕的问题之一。如果您使用堆内存,并超出了已分配块的边界,您很可能会触发段错误。(不是 100%:您的块可能与您先前分配的另一个块巧合地相邻)。但由于在栈上创建的变量总是彼此相邻的,因此越界写入可能会更改另一个变量的值。我已经学会了,每当感觉我的程序停止遵守逻辑规则时,那就可能是缓冲区溢出。
- Peter
1
alloca有多可移植?例如,它在Windows上工作吗?它只适用于类Unix操作系统吗? - Peter Mortensen95
简单来说,栈是本地变量创建的地方。每次调用子例程时,程序计数器(指向下一条机器指令的指针)和任何重要寄存器(有时还包括参数)都会被推入栈中。然后,在子例程内部的任何本地变量都会被推入栈中(并从那里使用)。当子例程完成时,所有这些东西都会从栈中弹出。PC和寄存器数据在弹出时会被放回原处,所以你的程序可以继续运行。
堆是动态内存分配的区域(采用显式的“new”或“allocate”调用)。它是一种特殊的数据结构,可以跟踪各种大小的内存块及其分配状态。
在“经典”系统中,RAM的布局是栈指针从内存底部开始,堆指针从顶部开始,并向彼此增长。如果它们重叠,则会耗尽RAM。但是,这在现代多线程操作系统中不起作用。每个线程都必须有自己的栈,而这些栈可以动态创建。
- T.E.D.
87
来自WikiAnwser。
栈
当一个函数或方法调用另一个函数,而后者又调用另一个函数,以此类推,所有这些函数的执行都保持挂起状态,直到最后一步函数返回其值。
这些挂起的函数调用链就是栈,因为栈中的元素(函数调用)彼此依赖。
在异常处理和线程执行中考虑栈是很重要的。
堆
堆只是程序用于存储变量的内存。 堆的元素(变量)彼此没有依赖关系,并且可以随时随机访问。
- Chenster
58
Stack 栈
- 非常快的访问速度
- 不需要显式地释放变量
- CPU高效管理空间,内存不会变得碎片化
- 只限于本地变量
- 栈大小有限制(根据操作系统)
- 不能调整变量大小
Heap 堆
- 可以全局访问变量
- 没有内存大小的限制
- (相对)较慢的访问速度
- 无法保证空间的有效利用,内存可能随着分配和释放内存块而逐渐变得碎片化
- 你必须管理内存(负责分配和释放变量)
- 可以使用realloc()调整变量的大小
- unknown
56
简而言之
栈用于静态内存分配,堆用于动态内存分配,两者都存储在计算机的RAM中。
详细信息
栈
栈是一种“后进先出”(Last In, First Out,LIFO)的数据结构,由CPU密切管理和优化。每次函数声明一个新变量时,它会被“推入”栈中。然后每次函数退出时,该函数推送到栈上的所有变量都将被释放(即删除)。一旦栈变量被释放,该内存区域就可以为其他栈变量提供空间。
使用栈存储变量的优点是,内存由系统自动管理。您不必手动分配内存,也不必在不再需要时释放内存。此外,由于CPU有效地组织了栈内存,因此从栈变量读取和写入非常快速。
更多信息请查看这里。
堆
堆是计算机内存的一个区域,不会被自动管理,也不像CPU那样受到严格的管理。它是一个更自由浮动的内存区域(并且更大)。要在堆上分配内存,必须使用内置的C函数malloc()或calloc()。一旦你在堆上分配了内存,就需要使用free()来释放那些不再需要的内存。
如果你未能这样做,你的程序将出现所谓的内存泄漏。也就是说,堆上的内存仍然被保留(并且不可用于其他进程)。正如我们将在调试部分中看到的那样,有一种名为Valgrind的工具可以帮助你检测内存泄漏。
与栈不同,堆对变量大小没有限制(除了计算机的显然物理限制)。访问堆内存稍微慢一些,因为必须使用指针来访问堆内存。我们很快就会讨论指针。
与栈不同,在堆上创建的变量可被程序中任何函数访问。堆变量本质上具有全局作用域。
可以在这里找到更多信息。
栈上分配的变量直接存储在内存中,访问该内存非常快,其分配在程序编译时处理。当一个函数或方法调用另一个函数,后者再调用另一个函数等等时,所有这些函数的执行都保持暂停状态,直到最后一个函数返回其值。栈始终按LIFO顺序保留,最近保留的块始终是下一个要释放的块。这使得跟踪堆栈非常简单,从堆栈中释放块只需要调整一个指针。
在堆上分配的变量在运行时分配其内存,访问该内存有点慢,但堆的大小仅受虚拟内存大小的限制。堆的元素彼此没有依赖关系,可以随时随意地随机访问。您可以随时分配块并随时释放它。这使得跟踪堆的哪些部分在任何给定时间分配或空闲变得更加复杂。
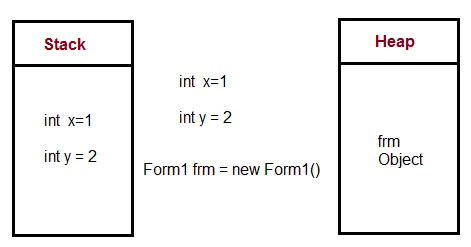
如果你在编译时知道需要分配多少数据,并且数据量不太大,那么可以使用栈。如果你不确定在运行时需要分配多少数据,或者需要分配大量数据,则可以使用堆。
在多线程情况下,每个线程都有自己完全独立的栈,但它们会共享堆。栈是线程特定的,而堆是应用程序特定的。在异常处理和线程执行中考虑栈非常重要。
每个线程都有一个栈,而通常只有一个堆供应用程序使用(尽管为不同类型的分配使用多个堆并不罕见)。

此外,这里 和 这里 给出了更详细的信息。
现在来看看你问题的答案。
它们在多大程度上受操作系统或语言运行时控制?
当线程创建时,操作系统为每个系统级线程分配堆栈。通常,语言运行时会调用操作系统来为应用程序分配堆。
可以在这里找到更多信息。
它们的范围是什么?
已在顶部给出。
"如果您知道编译时需要分配多少数据,并且数据量不太大,则可以使用堆栈。如果您不知道运行时需要分配多少数据,或者需要分配大量数据,则可以使用堆。"
可以在这里找到更多信息。
当线程创建时,操作系统设置堆栈的大小。堆的大小在应用程序启动时设置,但它可以随着需要增长(分配器从操作系统请求更多内存)。是什么决定了它们的大小?
堆栈分配要快得多,因为它实际上只是移动堆栈指针。使用内存池,您可以获得与堆分配相当的性能,但这会带来一些额外的复杂性和自身的问题。什么能让代码更快?
此外,堆栈与堆不仅是性能考虑;它还告诉您有关对象预期寿命的很多信息。
详细信息可以在这里找到。
- Abrar Jahin
54
OK, 简单来说,它们意味着有序和无序...!
Stack(栈):在栈项目中,物品会堆叠在顶部,这意味着处理速度更快、更高效!因此,始终有一个索引指向特定的项,处理速度也会更快,并且项目之间存在关联!...
Heap(堆):没有顺序,处理速度会变慢,值混乱地放在一起,没有特定的顺序或索引...它们是随机的,它们之间没有关系...因此执行和使用时间可能会有所不同...
我还创建了下面的图片,以展示它们可能的样子:

- Alireza
1
在这个上下文中,“relationship”和“order”是什么意思? - Farid
47
堆叠(stack)、堆(heap)和数据(data)在虚拟内存中的每个进程中:

- Yousha Aleayoub
37
在20世纪80年代,UNIX像兔子一样繁衍,大公司都在自己开发。
埃克森美孚有一个,失落在历史中的许多品牌也有。
内存布局由许多实现者决定。
一个典型的C程序在内存中是平面布局,可以通过更改brk()值来增加空间。 通常,堆位于这个brk值下方,并且增加brk会增加可用堆的数量。
单个堆栈通常位于堆下方的一个内存区域, 其中包含了没有价值的内容,直到下一个固定内存块的顶部。 这个下一个块通常是代码,可以被其时代的著名黑客之一在堆栈数据中覆盖。
一个典型的内存块是BSS(零值块), 其中一个制造商的产品意外地没有清零。 还有一个包含初始化值的DATA,包括字符串和数字。 第三个是CODE,其中包括CRT(C运行时),main,函数和库。
UNIX中虚拟内存的出现改变了许多限制。 现在这些块没有客观理由需要连续, 或者大小固定,或以特定方式排序。 当然,在UNIX之前是Multics,它没有受到这些限制的困扰。 这里是一个示意图,显示了那个时代的一个内存布局。
一个典型的C程序在内存中是平面布局,可以通过更改brk()值来增加空间。 通常,堆位于这个brk值下方,并且增加brk会增加可用堆的数量。
单个堆栈通常位于堆下方的一个内存区域, 其中包含了没有价值的内容,直到下一个固定内存块的顶部。 这个下一个块通常是代码,可以被其时代的著名黑客之一在堆栈数据中覆盖。
一个典型的内存块是BSS(零值块), 其中一个制造商的产品意外地没有清零。 还有一个包含初始化值的DATA,包括字符串和数字。 第三个是CODE,其中包括CRT(C运行时),main,函数和库。
UNIX中虚拟内存的出现改变了许多限制。 现在这些块没有客观理由需要连续, 或者大小固定,或以特定方式排序。 当然,在UNIX之前是Multics,它没有受到这些限制的困扰。 这里是一个示意图,显示了那个时代的一个内存布局。
- jlettvin
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
rlimit_stack等系统变量和行为的某些方面。另请参见 Red Hat 的 Issue 1463241。 - jww