为什么BFS和DFS的运行时间是O(V + E),特别是当有一个节点指向一个可以从顶点到达的节点的有向边时,例如在以下网站中的此示例。
http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/GraphAlgor/depthSearch.htm
http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/GraphAlgor/depthSearch.htm
在图G={V,E}中,E是所有边的集合。因此,|E|表示图中所有边的数量。
仅凭这一点就足以说明总复杂度不能是|V|乘以|E|,因为我们不会为每个顶点遍历图中的所有边。
在邻接表表示法中,对于每个顶点v,我们只遍历与其相邻的节点。
|V|+|E|中的|V|因子似乎来自于所执行的队列操作次数。
请注意,算法的复杂度取决于所使用的数据结构。实际上,我们正在访问表示图的每个信息块,这就是为什么对于矩阵表示法的图,复杂度变为了V平方。
引用Cormen的话:
“入队和出队的操作时间为O(1),因此花费在队列操作上的总时间为O(V)。由于每个顶点的邻接表仅在其出队时被扫描,因此每个邻接表最多被扫描一次。由于所有邻接表的长度之和为Θ(E),因此在扫描邻接表上花费的总时间为O(E)。初始化的开销为O(V),因此BFS的总运行时间为O(V+E)。”
这个问题耗费了我4个小时的时间,但最终,我认为我有了一个简单的获取图片的方法,一开始我想说是 O(V*E)。
总结一下在Cormen中找到的算法,它与http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/GraphAlgor/breadthSearch.htm上的算法相同,具体如下:
for (vi in V)
{
Some O(1) instructions
for ( e in Adj(vi) ) {
Some O(1) instructions
}
}
您最多访问每条边两次。共有E条边。因此,将进行2*E次边访问操作。再加上那些没有边或者换句话说,度数为0的节点。最多可能有V个这样的节点。所以,复杂度变成了O(2*E + V) = O(E + V)
当您将图形表示为相邻列表的数据结构时,其变得清晰明了。
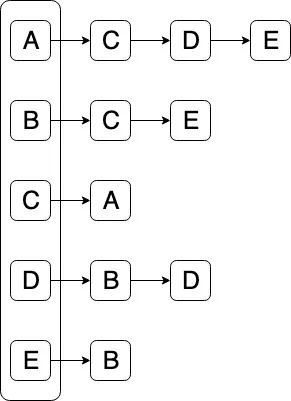
您会看到顶点:A,B,C,D,E和每个顶点/节点的相邻顶点作为从这些顶点开始的列表。如果是循环图,则必须“查看”所有框以检查其是否已被“访问”,或者如果它是类似树的图,则只需遍历所有子项。
private static void visitUsingDFS(Node startNode) {
if(startNode.visited){
return;
}
startNode.visited = true;
System.out.println("Visited "+startNode.data);
for(Node node: startNode.AdjacentNodes){
if(!node.visited){
visitUsingDFS(node);
}
}
}