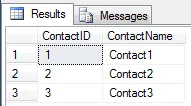
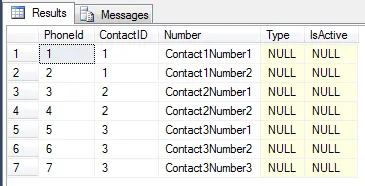
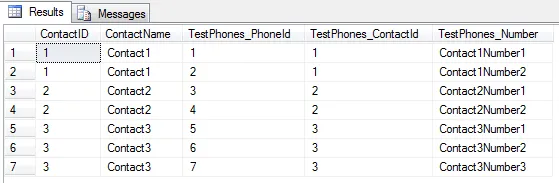
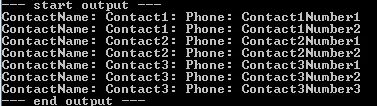
我编写了以下代码来实现一对多的关系,但是它没有起作用:
using (var connection = new SqlConnection(connectionString))
{
connection.Open();
IEnumerable<Store> stores = connection.Query<Store, IEnumerable<Employee>, Store>
(@"Select Stores.Id as StoreId, Stores.Name,
Employees.Id as EmployeeId, Employees.FirstName,
Employees.LastName, Employees.StoreId
from Store Stores
INNER JOIN Employee Employees ON Stores.Id = Employees.StoreId",
(a, s) => { a.Employees = s; return a; },
splitOn: "EmployeeId");
foreach (var store in stores)
{
Console.WriteLine(store.Name);
}
}
有人能发现错误吗?
编辑:
这些是我的实体:
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public double Price { get; set; }
public IList<Store> Stores { get; set; }
public Product()
{
Stores = new List<Store>();
}
}
public class Store
{
public int Id { get; set; }
public string Name { get; set; }
public IEnumerable<Product> Products { get; set; }
public IEnumerable<Employee> Employees { get; set; }
public Store()
{
Products = new List<Product>();
Employees = new List<Employee>();
}
}
编辑:
我将查询更改为:
IEnumerable<Store> stores = connection.Query<Store, List<Employee>, Store>
(@"Select Stores.Id as StoreId ,Stores.Name,Employees.Id as EmployeeId,
Employees.FirstName,Employees.LastName,Employees.StoreId
from Store Stores INNER JOIN Employee Employees
ON Stores.Id = Employees.StoreId",
(a, s) => { a.Employees = s; return a; }, splitOn: "EmployeeId");
我摆脱了异常!但是员工根本没有被映射。我仍然不确定第一个查询在 IEnumerable<Employee> 方面有什么问题。