解决方案
我最终成功破解了它,实现了一种真正的向量化解决方案,使用逻辑索引从输入矩阵中选择要求和的元素。这种神奇的方法是通过bsxfun及其可选的函数句柄@mod实现的。代码如下:
[m,n] = size(M);
mask = bsxfun(@mod,1:n,(1:m)')==1;
mask(1,:) = 1;
sumvals = sum(mask.*M,2);
基准测试
在这个基准测试部分中,我包含了四种方法 - 早期在本篇文章中列出的方法及其GPU端口版本,以及在其他解决方案中列出的基于arrayfun和sparse的方法。
基准测试使用了三组输入数据 -
Set 1:将输入矩阵的行数保持为列数的10倍数,与问题中所使用的输入矩阵相同。Set 2:扩展行数,使行数现在是列数的10x倍。这将真正测试循环代码,因为在这种情况下迭代次数会更多。Set 3:这个集合是set2的扩展,进一步增加了行数,因此将是真正向量化方法与其他方法之间的另一个重要测试。
用于基准测试的函数代码如下所示 -
function sumvals = sumrows_stepped_bsxfun(M)
//... same as the code posted earlier
return
function sumvals = sumrows_stepped_bsxfun_gpu(M)
gM = gpuArray(M);
[m,n] = size(gM);
mask = bsxfun(@mod,gpuArray.colon(1,n),gpuArray.colon(1,m)')==1;
sumvals = gather(sum(mask.*gM,2));
sumvals(1) = sum(M(1,:));
return
function S = sumrows_stepped_arrayfun(M)
[m,n] = size(M);
S = arrayfun(@(x) sum(M(x,1:x:n)), 1:m);
return
function B = sumrows_stepped_sparse(M)
sz = size(M);
A=sparse(sz(1),sz(2));
for n=1:sz(1),
A(n, 1:n:end)=1;
end
B=full(sum(M.*A,2));
return
请注意,
timeit 用于计时
CPU based 代码,而
gputimeit 用于
GPU based 代码。
用于测试的系统配置 -
MATLAB Version: 8.3.0.532 (R2014a)
Operating System: Windows 7
RAM: 3GB
CPU Model: Intel® Pentium® Processor E5400 (2M Cache, 2.70 GHz)
GPU Model: GTX 750Ti 2GB
得到的基准测试结果如下 -
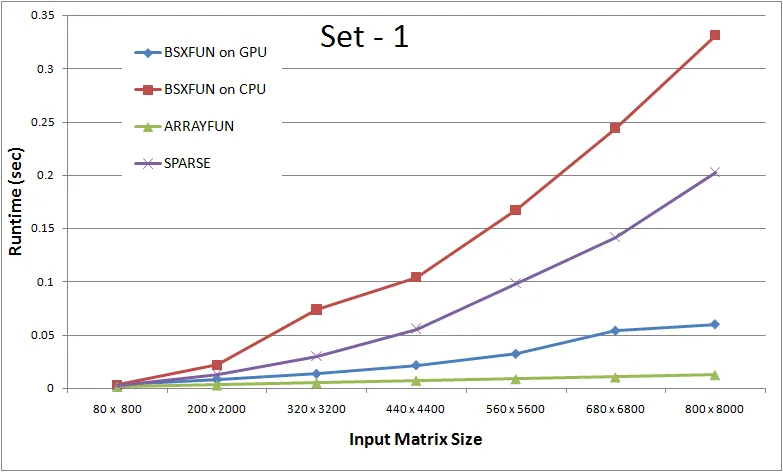
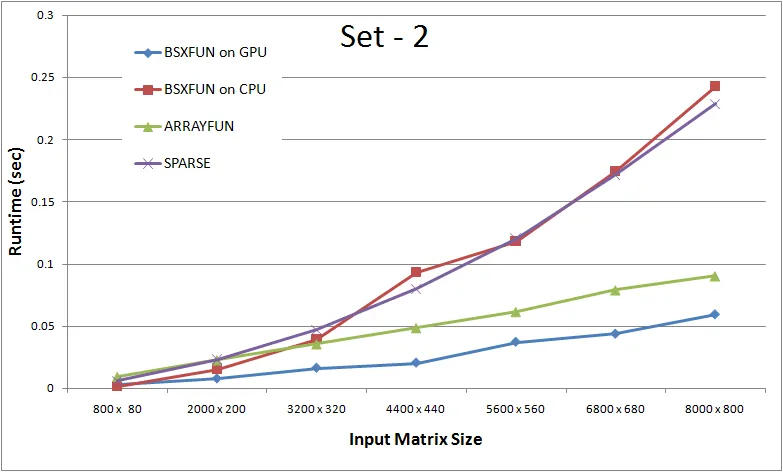
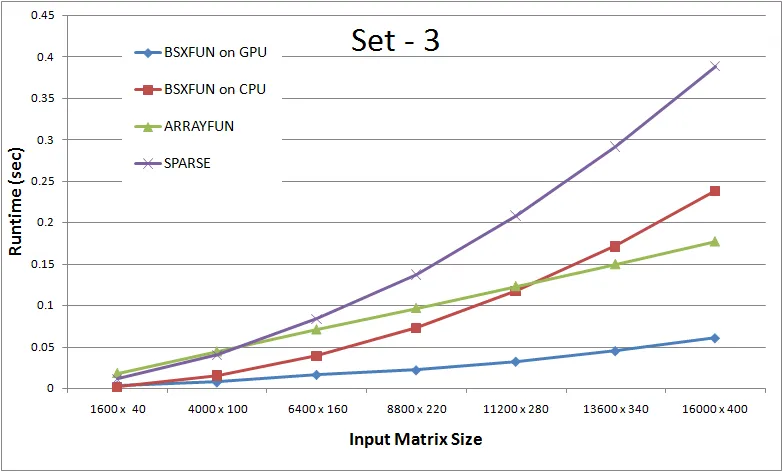
结论:
1. 对于行数小于列数的数据大小和迭代次数较少的情况下,循环代码似乎更占优势。
2. 随着行数的增加,真正矢量化方法的优点变得更加明显。你会发现,在非矢量化方法中,基于CPU的“bsxfun”方法在第3组数据集上表现良好,直到达到“12000 x 300”的标记时,因为“bsxfun”创建了巨大的逻辑掩码,此时内存带宽需求变得太高以应对“bsxfun”的计算能力。这是有道理的,因为定义上,矢量化操作意味着一次处理许多元素,因此内存带宽是必要的。因此,如果您有一台更好的机器和更多的RAM,则“12000 x 300”的标记应该进一步延长。
3. 如果您可以进一步扩展行数,则只要内存带宽得到控制,矢量化解决方案的好处就会变得更加清晰。
基准测试代码如下:
clear all; clc; close all
outputfile = 'results.xlsx';
delete(outputfile);
base_datasize_array = 40:60:400;
methods = {'BSXFUN on GPU','BSXFUN on CPU','ARRAYFUN','SPARSE'};
num_approaches = numel(methods);
num_sets = 3;
timeall_all = zeros(num_approaches,numel(base_datasize_array),num_sets);
datasize_lbs = cell(numel(base_datasize_array),num_sets);
for set_id = 1:num_sets
switch set_id
case 1
N1_arr = base_datasize_array*2;
N2_arr = N1_arr*10;
case 2
N2_arr = base_datasize_array*2;
N1_arr = N2_arr*10;
case 3
N2_arr = base_datasize_array;
N1_arr = N2_arr*40;
end
timeall = zeros(num_approaches,numel(N1_arr));
for iter = 1:numel(N1_arr)
M = rand(N1_arr(iter),N2_arr(iter));
f = @() sumrows_stepped_bsxfun_gpu(M);
timeall(1,iter) = gputimeit(f); clear f
f = @() sumrows_stepped_bsxfun(M);
timeall(2,iter) = timeit(f); clear f
f = @() sumrows_stepped_arrayfun(M);
timeall(3,iter) = timeit(f); clear f
f = @() sumrows_stepped_sparse(M);
timeall(4,iter) = timeit(f); clear f
end
timeall_all(:,:,set_id) = timeall;
wp = repmat({' '},numel(N1_arr),1);
datasize_lbs(:,set_id) = strcat(cellstr(num2str(N1_arr.')),' x ',...
wp,cellstr(num2str(N2_arr.')));
end
for set_id=1:num_sets
out_cellarr = cell(numel(methods)+1,numel(N1_arr)+1);
out_cellarr(1,1) = {'Methods'};
out_cellarr(2:end,1) = methods;
out_cellarr(1,2:end) = datasize_lbs(:,set_id);
out_cellarr(2:end,2:end) = cellfun(@(x) num2str(x),...
num2cell(timeall_all(:,:,set_id)),'Uni',0);
xlswrite(outputfile, out_cellarr,set_id);
end