我有一些在JavaScript中作为Uint8Array元素范围存在的UTF-8编码数据。是否有一种高效的方法将其解码为常规JavaScript字符串(我相信JavaScript使用16位Unicode)?我不想逐个字符添加,因为字符串连接将变得CPU密集。
21个回答
406
TextEncoder 和 TextDecoder 是来自编码标准的函数。它们可通过stringencoding 库进行 polyfill,用于字符串和 ArrayBuffers 之间的转换:
var uint8array = new TextEncoder().encode("someString");
var string = new TextDecoder().decode(uint8array);
- Vincent Scheib
16
52如果有像我这样懒的人,可以执行
npm install text-encoding,然后输入以下代码:var textEncoding = require('text-encoding'); var TextDecoder = textEncoding.TextDecoder;。但我不感兴趣。 - Evan Hu24注意 npm 的 text-encoding 库,Webpack Bundle Analyzer 显示该库非常庞大。 - wayofthefuture
1从例子中:
const { StringDecoder } = require('string_decoder');
const decoder = new StringDecoder('utf8');
const cent = Buffer.from([0xC2, 0xA2]);
console.log(decoder.write(cent));请参考:https://nodejs.org/api/string_decoder.html - curist
19请注意,Node.js v11 版本已经添加了
TextEncoder/TextDecoder API,因此如果你只针对当前的 Node 版本,就不需要安装任何额外的包。 - Loilo显示剩余11条评论
53
这应该可以正常工作:
// http://www.onicos.com/staff/iz/amuse/javascript/expert/utf.txt
/* utf.js - UTF-8 <=> UTF-16 convertion
*
* Copyright (C) 1999 Masanao Izumo <iz@onicos.co.jp>
* Version: 1.0
* LastModified: Dec 25 1999
* This library is free. You can redistribute it and/or modify it.
*/
function Utf8ArrayToStr(array) {
var out, i, len, c;
var char2, char3;
out = "";
len = array.length;
i = 0;
while(i < len) {
c = array[i++];
switch(c >> 4)
{
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
// 0xxxxxxx
out += String.fromCharCode(c);
break;
case 12: case 13:
// 110x xxxx 10xx xxxx
char2 = array[i++];
out += String.fromCharCode(((c & 0x1F) << 6) | (char2 & 0x3F));
break;
case 14:
// 1110 xxxx 10xx xxxx 10xx xxxx
char2 = array[i++];
char3 = array[i++];
out += String.fromCharCode(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
}
}
return out;
}
相比其他解决方案,它更加干净,因为它不使用任何黑科技,也不依赖于浏览器JS函数,例如在其他JS环境中也可以工作。
查看JSFiddle演示。
- Albert
5
6这似乎有点慢,但这是我在整个宇宙中找到的唯一有效的片段。不错的发现和采用! - Redsandro
8我不明白为什么这个帖子没有更多的赞。它似乎非常合理,适用于小片段的UTF-8编码。根据其他人的说法,异步Blob + Filereader在处理大文本时效果很好。 - DanHorner
4问题是如何在不使用字符串连接的情况下完成这个任务。 - Jack Wester
7功能很好,但它无法处理4个或更多字节的序列,例如
fromUTF8Array([240,159,154,133])结果为空(而fromUTF8Array([226,152,131])→"☃")。 - unhammer2为什么第8、9、10和11案例被排除了?有特别的原因吗?而第15个案例也是可能的,对吧?15(1111)表示使用了4个字节,是吗? - RaR
49
这是我使用的:
var str = String.fromCharCode.apply(null, uint8Arr);
- dlchambers
9
47在处理更大的文本时,会抛出“RangeError”错误。错误消息为“最大调用栈大小超过限制”。 - Redsandro
1如果您正在将大型Uint8Arrays转换为二进制字符串并且出现RangeError,请参见https://dev59.com/Qmcs5IYBdhLWcg3wmlSk#12713326中的Uint8ToString函数。 - yonran
1当我向IE 11输入300k+字符时,它会抛出“SCRIPT28:堆栈空间不足”错误,Chrome 39会抛出“RangeError”错误。Firefox 33则没有问题。所有三个浏览器都可以处理100k+的字符。 - Sheepy
2这并不能从https://en.wikipedia.org/wiki/UTF-8上的示例Unicode字符产生正确的结果。例如,String.fromCharCode.apply(null, new Uint8Array([0xc2, 0xa2]))不能产生¢。 - Vincent Scheib
显示剩余4条评论
34
在NodeJS中,我们可以使用缓冲区(Buffers),并且使用它们进行字符串转换非常容易。更好的是,将Uint8Array转换为Buffer也很容易。尝试这段代码,在涉及Uint8Arrays的任何转换中,对我来说在Node中都有效:
let str = Buffer.from(uint8arr.buffer).toString();
我们只是从Uint8Array中提取ArrayBuffer,然后将其转换为适当的NodeJS缓冲区。然后我们将缓冲区转换为字符串(如果需要可以加入十六进制或base64编码)。
如果我们想要从字符串转换回Uint8Array,那么我们会这样做:
let uint8arr = new Uint8Array(Buffer.from(str));
请注意,如果在转换为字符串时声明了像base64这样的编码方式,则必须使用Buffer.from(str, "base64")来使用base64或者使用其他编码方式。
在浏览器中没有模块的情况下,这将无法工作! 浏览器中不存在NodeJS缓冲区,因此除非您在浏览器中添加缓冲区功能,否则此方法将无法工作。不过,这实际上很容易做到,只需使用像这个这样的模块,它既小又快速!
- arctic_hen7
27
在 Node 中,"Buffer 实例也是 Uint8Array 实例",因此在这种情况下buf.toString()也能正常工作。
- kpowz
6
1简单而优雅,我不知道
Buffer也是Uint8Array。谢谢! - LeOn - Han Li11在浏览器端,Uint8Array.toString() 无法将一个 utf-8 字符串编译出来,它会列出数组中的数字值。所以,如果你有一个来自另一个不是 Buffer 的来源的 Uint8Array,你需要创建一个 Buffer 来做魔法:
Buffer.from(uint8array).toString('utf-8')。请注意保持原文意思,并使翻译通俗易懂。 - Joachim Lous那么使用“Buffer.prototype.toString.call(uint8array, 'utf8')”如何?这样可以避免创建新的缓冲实例。 - user11390576
3这在Chrome中不起作用。
Buffer仅适用于nodejs。 - John Henckel这个答案令人困惑,因为OP一开始就有一个
Uint8Array。所有的缓冲区都是Uint8Arrays,但并非所有的Uint8Arrays都是缓冲区。Joachim的答案是正确的,但不幸的是,根据Node的文档,Buffer.from在这种情况下会创建一个副本,而不是视图。 - Coderer21
这段代码是从Chrome的示例应用程序中找到的,它适用于较大的数据块,并且可以接受异步转换。
/**
* Converts an array buffer to a string
*
* @private
* @param {ArrayBuffer} buf The buffer to convert
* @param {Function} callback The function to call when conversion is complete
*/
function _arrayBufferToString(buf, callback) {
var bb = new Blob([new Uint8Array(buf)]);
var f = new FileReader();
f.onload = function(e) {
callback(e.target.result);
};
f.readAsText(bb);
}
- Will Scott
1
3就像你所说的,除非要转换的缓冲区真的非常非常大,否则这个方法的表现会很差。例如,在 V8 中实现的同步 UTF-8 到 wchar 转换一个简单字符串(比如 10-40 字节)应该不到一微秒,而我猜你的代码可能需要数百倍于此。还是非常感谢。 - Jack Wester
18
虽然Albert提供的解决方案对于不频繁调用且仅用于中等大小数组的函数效果良好,但对于大型数组则极其低效。以下是一种增强版的vanilla JavaScript解决方案,适用于Node和浏览器,并具有以下优点:
• 对所有八位字节数组大小都能高效工作
• 不产生任何中间丢弃字符串
• 在现代JS引擎上支持4字节字符(否则将替换为“?”)
var utf8ArrayToStr = (function () {
var charCache = new Array(128); // Preallocate the cache for the common single byte chars
var charFromCodePt = String.fromCodePoint || String.fromCharCode;
var result = [];
return function (array) {
var codePt, byte1;
var buffLen = array.length;
result.length = 0;
for (var i = 0; i < buffLen;) {
byte1 = array[i++];
if (byte1 <= 0x7F) {
codePt = byte1;
} else if (byte1 <= 0xDF) {
codePt = ((byte1 & 0x1F) << 6) | (array[i++] & 0x3F);
} else if (byte1 <= 0xEF) {
codePt = ((byte1 & 0x0F) << 12) | ((array[i++] & 0x3F) << 6) | (array[i++] & 0x3F);
} else if (String.fromCodePoint) {
codePt = ((byte1 & 0x07) << 18) | ((array[i++] & 0x3F) << 12) | ((array[i++] & 0x3F) << 6) | (array[i++] & 0x3F);
} else {
codePt = 63; // Cannot convert four byte code points, so use "?" instead
i += 3;
}
result.push(charCache[codePt] || (charCache[codePt] = charFromCodePt(codePt)));
}
return result.join('');
};
})();
- Bob Arlof
2
2最佳解决方案在这里,因为它还处理4字节字符(例如表情符号)
谢谢! - fiffy
2这个的反向操作是什么? - simbo1905
9
Uint8Array 转为字符串
let str = Buffer.from(key.secretKey).toString('base64');
将字符串转换为Uint8Array
let uint8arr = new Uint8Array(Buffer.from(data,'base64'));
- Swaroop Maddu
7
按照@Sudhir所说的做,然后从逗号分隔的数字列表中获取一个字符串,使用以下代码:
for (var i=0; i<unitArr.byteLength; i++) {
myString += String.fromCharCode(unitArr[i])
}
如果这仍然相关,这将为您提供所需的字符串。
- shuki
6
抱歉,没有注意到你在最后一句中说你不想逐个添加一个字符。希望这能帮助那些不关心 CPU 使用率的人。 - shuki
16不进行UTF8解码。 - Albert
1更简短的代码:
String.fromCharCode.apply(null, unitArr);。正如提到的那样,它不能处理UTF8编码,但是如果您只需要ASCII支持而没有访问TextEncoder / TextDecoder,则有时这足够简单。 - Ten Bitcomb答案提到了@Sudhir,但我在页面中搜索却没有找到这样的回答。因此最好将他说的内容嵌入其中。 - Joakim
这会导致较长字符串的性能非常糟糕。不要在字符串上使用 + 运算符。 - Max
6
我很沮丧地发现,人们没有展示如何双向操作,或者展示在非平凡的UTF8字符串上工作的情况。我在codereview.stackexchange.com上找到了一些代码,它可以很好地工作。我用它将古代符文转换为字节,对字节进行测试,然后将其转换回字符串。可工作的代码在这里的Github上。我为了清晰起见重命名了方法:
// https://codereview.stackexchange.com/a/3589/75693
function bytesToSring(bytes) {
var chars = [];
for(var i = 0, n = bytes.length; i < n;) {
chars.push(((bytes[i++] & 0xff) << 8) | (bytes[i++] & 0xff));
}
return String.fromCharCode.apply(null, chars);
}
// https://codereview.stackexchange.com/a/3589/75693
function stringToBytes(str) {
var bytes = [];
for(var i = 0, n = str.length; i < n; i++) {
var char = str.charCodeAt(i);
bytes.push(char >>> 8, char & 0xFF);
}
return bytes;
}
单元测试使用此UTF-8字符串:
// http://kermitproject.org/utf8.html
// From the Anglo-Saxon Rune Poem (Rune version)
const secretUtf8 = `ᚠᛇᚻ᛫ᛒᛦᚦ᛫ᚠᚱᚩᚠᚢᚱ᛫ᚠᛁᚱᚪ᛫ᚷᛖᚻᚹᛦᛚᚳᚢᛗ
ᛋᚳᛖᚪᛚ᛫ᚦᛖᚪᚻ᛫ᛗᚪᚾᚾᚪ᛫ᚷᛖᚻᚹᛦᛚᚳ᛫ᛗᛁᚳᛚᚢᚾ᛫ᚻᛦᛏ᛫ᛞᚫᛚᚪᚾ
ᚷᛁᚠ᛫ᚻᛖ᛫ᚹᛁᛚᛖ᛫ᚠᚩᚱ᛫ᛞᚱᛁᚻᛏᚾᛖ᛫ᛞᚩᛗᛖᛋ᛫ᚻᛚᛇᛏᚪᚾ᛬`;
请注意,该字符串长度仅为117个字符,但编码后的字节长度为234。
如果我取消注释console.log行,我可以看到解码的字符串与编码的字符串相同(通过Shamir的秘密共享算法传递的字节!)。
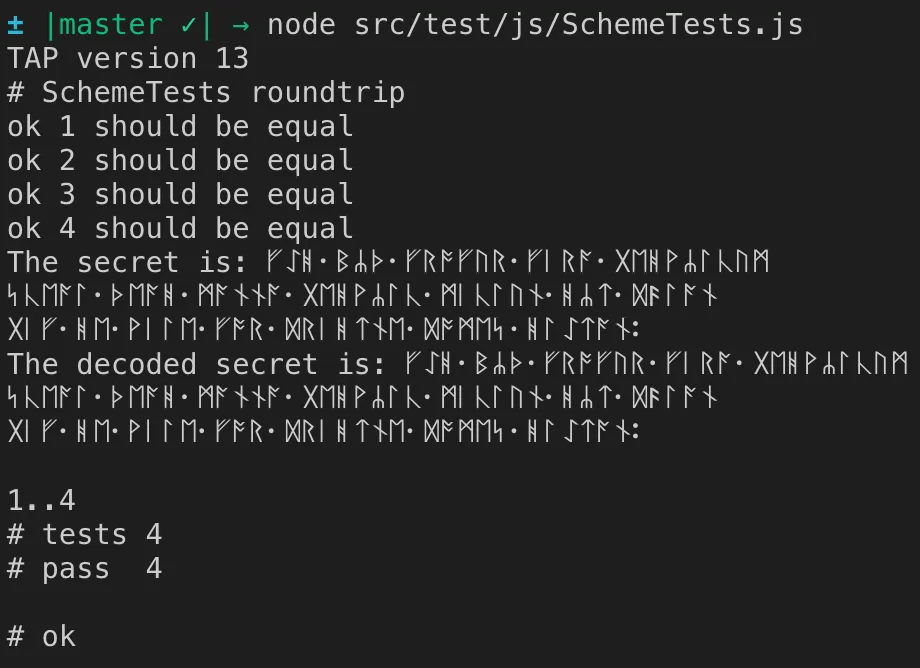
- simbo1905
5
1如果
chars太大,String.fromCharCode.apply(null, chars)会出错。 - Marc J. Schmidt这是普遍存在的问题还是只在某些浏览器中出现?是否有相关文档记录? - simbo1905
1但要注意:使用apply的方式可能会超出JavaScript引擎的参数长度限制。使用过多参数(即超过数万个参数)应用函数的后果因引擎而异。(JavaScriptCore引擎有一个硬编码参数限制为65536。) - Marc J. Schmidt
谢谢。在我的情况下,我正在处理较小的字符串加密,所以没有问题。你有解决长字符串的方法吗? :-) - simbo1905
2解决方案是将字符分批处理,每批64k。 - Marc J. Schmidt
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 在JavaScript中将Uint8Array转换为BigInt
- 5 在NodeJs中将Uint8Array转换为Uint16Array
- 3 在JavaScript中将uint8array转换为double
- 7 JavaScript:UInt8Array转换为Float32Array
- 6 在JavaScript中将字符串转换为Uint8Array
- 9 在Javascript中将图像转换为Uint8Array
- 9 从Uint8Array转换为字符串,以及从字符串转换回Uint8Array
- 4 如何在JavaScript中将Uint8Array转换为浮点数?
- 3 在Angular中将文件转换为uInt8Array
- 4 在JavaScript中将Uint8Array转换为Float64Array
u8array.toString()。当您调用fs.readFile时,它会暴露Uint8Array对象。 - jcubicUint8Array对象,调用toString方法会返回逗号分隔的数字字符串,例如在Chrome 79中返回"91,50,48,49,57,45,"。 - kolenbuffer.toString("utf8", start, end)将 Node.js 中的Buffer转换为 JavaScript 字符串,其中end = start + length。不幸的是,浏览器没有Buffer,它们只有Uint8Array。因此,对于浏览器,您可以使用new TextDecoder().decode(uint8array.subarray(start, end))。这也适用于 Node.js,因为Buffer是Uint8Array的子类。 - Aadit M Shah