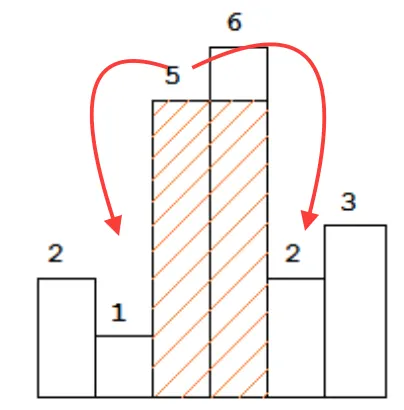
其他答案已经很好地介绍了使用两个堆栈的O(n)时间复杂度、O(n)空间复杂度的解决方案。对于这个问题,还有另一个角度提供了独立的O(n)时间复杂度、O(n)空间复杂度的解决方案,并且可能会更深入地解释为什么基于堆栈的解决方案有效。
关键思想是使用一种数据结构称为笛卡尔树。笛卡尔树是一种二叉树结构(虽然不是二叉搜索树),围绕输入数组构建而成。具体来说,笛卡尔树的根建立在数组的最小元素上,左右子树从最小值的左侧和右侧的子数组递归构建。
例如,这里有一个示例数组及其笛卡尔树:
+----------------------- 23 ------+
| |
+------------- 26 --+ +-- 79
| | |
31 --+ 53 --+ 84
| |
41 --+ 58 -------+
| |
59 +-- 93
|
97
+----+----+----+----+----+----+----+----+----+----+----+
| 31 | 41 | 59 | 26 | 53 | 58 | 97 | 93 | 23 | 84 | 79 |
+----+----+----+----+----+----+----+----+----+----+----+
笛卡尔树在这个问题中很有用的原因是,所提出的问题具有非常好的递归结构。首先看一下直方图中最低的矩形。对于最大矩形可能出现的位置,有三种情况:
它可能经过直方图中的最小值。在这种情况下,为了使其尽可能大,我们希望将其宽度设为整个数组的宽度。
它可能完全位于最小值左侧。在这种情况下,我们需要递归地处理最小值左侧的子数组以得到答案。
它可能完全位于最小值右侧。在这种情况下,我们需要递归地处理最小值右侧的子数组以得到答案。
注意,这种递归结构-找到最小值,在最小值左右的子数组中进行某些操作-与笛卡尔树的递归结构完全匹配。事实上,如果我们在开始时可以为整个数组创建一个笛卡尔树,则可以通过从根向下递归遍历笛卡尔树来解决此问题。在每个节点处,我们递归计算左右子数组中的最佳矩形,以及通过放置在最小值下方所得到的矩形,然后返回找到的最佳选项。
伪代码如下:
function largestRectangleUnder(int low, int high, Node root) {
if (low == high) return 0;
return max {
(high - low) * root.value,
largestRectangleUnder(low, root.index, root.left),
largestRectnagleUnder(root.index + 1, high, root.right)
}
}
一旦我们获得Cartesian树,此算法的时间复杂度为O(n),因为我们恰好访问每个节点并且每个节点只需进行O(1)次操作。
事实证明,有一种简单的线性时间算法可用于构建Cartesian树。您可能会想到“自然”的构建方法是扫描数组,找到最小值,然后递归地从左右子数组构建Cartesian树。问题在于查找最小值的过程非常昂贵,这可能需要Θ(n²)的时间。
构建Cartesian树的“快速”方法是从左到右扫描数组,逐个添加一个元素。该算法基于以下关于Cartesian树的观察结果:
首先,Cartesian树遵循堆属性:每个元素都小于或等于其子元素。原因在于,Cartesian树根是整个数组中最小的值,而其子元素是它们自己子数组中的最小元素,以此类推。
其次,如果对Cartesian树进行中序遍历,则可以按它们出现的顺序返回数组的元素。要了解为什么,请注意,如果对Cartesian树进行中序遍历,则首先访问最小值左侧的所有内容,然后是最小值,最后是最小值右侧的所有内容。这些访问以相同的方式递归进行,因此每个元素最终都按顺序被访问。
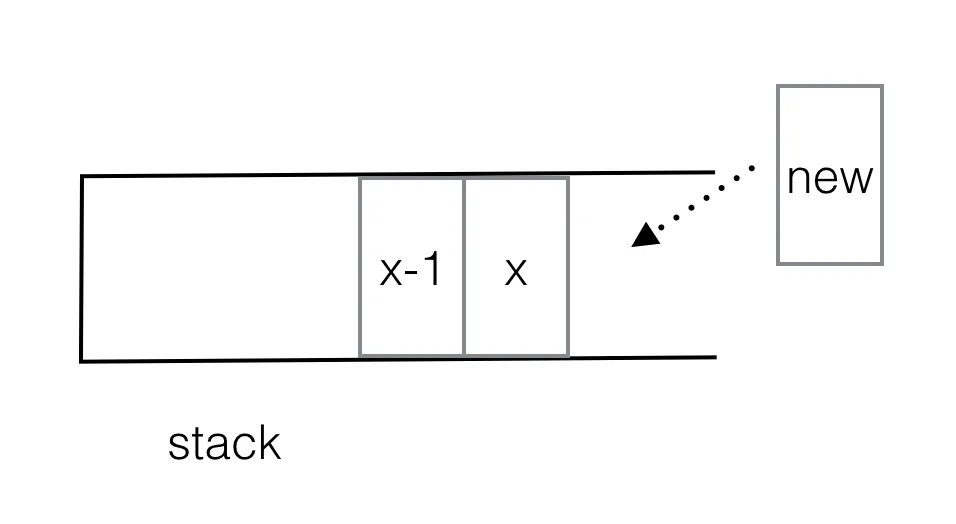
这两条规则为我们提供了有关从数组的前k个元素开始构建Cartesian树并且想要形成前k + 1个元素的Cartesian树时会发生什么的许多信息。该新元素将必须出现在Cartesian树的右脊柱上 - 即从根节点开始向右移动的部分 - 因为否则中序遍历中会有其它元素紧随其后。而且,在该右脊柱内,它必须以使其大于其上面的所有元素的方式放置,因为我们需要遵守堆属性。
实际上添加新节点到Cartesian树的方法是从树中最右侧的节点开始向上遍历,直到到达树的根节点或者找到具有更小值的节点。然后,将新值的左子节点设置为在其上方最后遍历的节点。
下面是在一个小数组上应用该算法的示例:
+
| 2 | 4 | 3 | 1 |
+
2成为根节点。
2 --+
|
4
4比2大,我们不能向上移动。追加到右侧。
+
| 2 | 4 | 3 | 1 |
+
2
|
|
4
3小于4,爬过它。 无法继续超过2,因为它比3小。 爬过以4为根的子树将移动到新值3的左侧,现在3成为最右边的节点。
+---+---+---+---+
| 2 | 4 | 3 | 1 |
+---+---+---+---+
+---------- 1
|
2 ------+
|
--- 3
|
4
1爬过根节点2后,以2作为根的整个树被移动到1的左侧,1现在成为新的根,同时也是最右侧的值。
+
| 2 | 4 | 3 | 1 |
+
虽然这似乎不是线性时间运行的——你可能会一遍又一遍地爬到树的根部吗?——但是你可以使用一个巧妙的论证来证明这是线性时间运行的。如果在插入过程中从右侧脊柱上跨越节点,那么该节点最终会被移出右侧脊柱,因此不能在将来的插入中重新扫描。因此,每个节点只会被扫描一次,因此总工作量是线性的。
现在关键的一步——实际实现这种方法的标准方式是通过维护一个对应于右侧脊柱上节点的值的堆栈来完成的。沿着节点“向上”和跨越节点相当于弹出堆栈中的一个元素。因此,构建笛卡尔树的代码看起来像这样:
Stack s;
for (each array element x) {
pop s until it's empty or s.top > x
push x onto the stack.
do some sort of pointer rewiring based on what you just did.
}
这里的堆栈操作可能会很熟悉,因为这些操作与其他答案中显示的完全相同。实际上,你可以将那些方法看作是在隐式构建笛卡尔树以及在此过程中运行上面显示的递归算法。
我认为了解笛卡尔树的好处在于它提供了一个非常好的概念框架,可以看到为什么该算法能正确地工作。如果你知道你正在运行笛卡尔树的递归遍历,那么更容易看出你保证找到最大的矩形。此外,知道笛卡尔树的存在还可以为解决其他问题提供有用的工具。笛卡尔树出现在针对区间最小查询问题设计快速数据结构时,并用于将后缀数组转换为后缀树。
这是一些Java代码,它实现了这个思想,由@Azeem提供!
import java.util.Stack;
public class CartesianTreeMakerUtil {
private static class Node {
int val;
Node left;
Node right;
}
public static Node cartesianTreeFor(int[] nums) {
Node root = null;
Stack<Node> s = new Stack<>();
for(int curr : nums) {
Node lastJumpedOver = null;
while(!s.empty() && s.peek().val > curr) {
lastJumpedOver = s.pop();
}
Node currNode = this.new Node();
currNode.val = curr;
if(s.isEmpty()) {
root = currNode;
}
else {
s.peek().right = currNode;
}
currNode.left = lastJumpedOver;
s.push(currNode);
}
return root;
}
public static void printInOrder(Node root) {
if(root == null) return;
if(root.left != null ) {
printInOrder(root.left);
}
System.out.println(root.val);
if(root.right != null) {
printInOrder(root.right);
}
}
public static void main(String[] args) {
int[] nums = new int[args.length];
for (int i = 0; i < args.length; i++) {
nums[i] = Integer.parseInt(args[i]);
}
Node root = cartesianTreeFor(nums);
tester.printInOrder(root);
}
}