我正在尝试将一个包含表格和图片的docx文件转换为pdf格式的文件。
我已经到处搜索但没有得到正确的解决方案,请提供正确的解决方案:
这是我尝试过的:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.poi.xwpf.converter.pdf.PdfConverter;
import org.apache.poi.xwpf.converter.pdf.PdfOptions;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
public class TestCon {
public static void main(String[] args) {
TestCon cwoWord = new TestCon();
System.out.println("Start");
cwoWord.ConvertToPDF("D:\\Test.docx", "D:\\Test1.pdf");
}
public void ConvertToPDF(String docPath, String pdfPath) {
try {
InputStream doc = new FileInputStream(new File(docPath));
XWPFDocument document = new XWPFDocument(doc);
PdfOptions options = PdfOptions.create();
OutputStream out = new FileOutputStream(new File(pdfPath));
PdfConverter.getInstance().convert(document, out, options);
System.out.println("Done");
} catch (FileNotFoundException ex) {
System.out.println(ex.getMessage());
} catch (IOException ex) {
System.out.println(ex.getMessage());
}
}
}
异常:
Exception in thread "main" java.lang.IllegalAccessError: tried to access method org.apache.poi.util.POILogger.log(ILjava/lang/Object;)V from class org.apache.poi.openxml4j.opc.PackageRelationshipCollection
at org.apache.poi.openxml4j.opc.PackageRelationshipCollection.parseRelationshipsPart(PackageRelationshipCollection.java:313)
at org.apache.poi.openxml4j.opc.PackageRelationshipCollection.<init>(PackageRelationshipCollection.java:162)
at org.apache.poi.openxml4j.opc.PackageRelationshipCollection.<init>(PackageRelationshipCollection.java:130)
at org.apache.poi.openxml4j.opc.PackagePart.loadRelationships(PackagePart.java:559)
at org.apache.poi.openxml4j.opc.PackagePart.<init>(PackagePart.java:112)
at org.apache.poi.openxml4j.opc.PackagePart.<init>(PackagePart.java:83)
at org.apache.poi.openxml4j.opc.PackagePart.<init>(PackagePart.java:128)
at org.apache.poi.openxml4j.opc.ZipPackagePart.<init>(ZipPackagePart.java:78)
at org.apache.poi.openxml4j.opc.ZipPackage.getPartsImpl(ZipPackage.java:239)
at org.apache.poi.openxml4j.opc.OPCPackage.getParts(OPCPackage.java:665)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:274)
at org.apache.poi.util.PackageHelper.open(PackageHelper.java:39)
at org.apache.poi.xwpf.usermodel.XWPFDocument.<init>(XWPFDocument.java:121)
at test.TestCon.ConvertToPDF(TestCon.java:31)
at test.TestCon.main(TestCon.java:25)
我的要求是创建一个Java代码,将现有的docx文档转换为带有正确格式和对齐方式的pdf。
请提供建议。
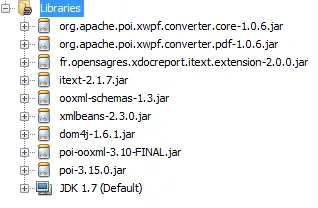
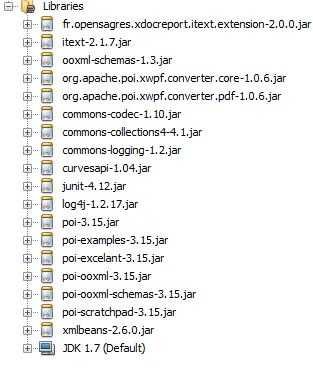
使用的Jars:
com.lowagie在你的异常中。这意味着你使用的是一个古老的 iText 版本,2.1.7 或更早版本,已经至少有8年历史了。既然你似乎信任 Bruno Lowagie 的专业知识,那么你应该熟悉他对仍在使用如此旧的 iText 版本的人的看法。 - Amedee Van Gasse