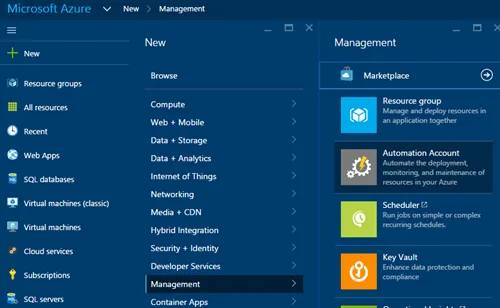
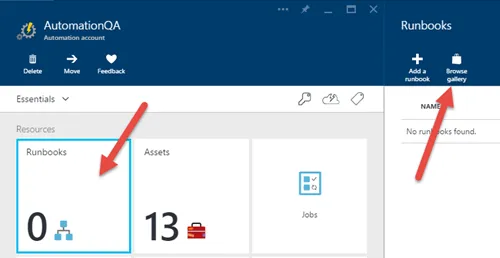
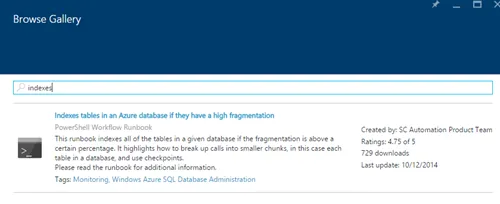
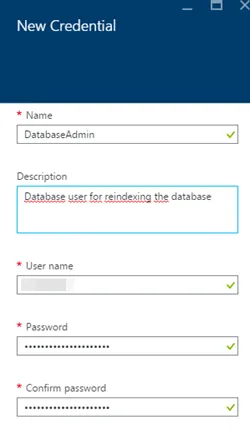
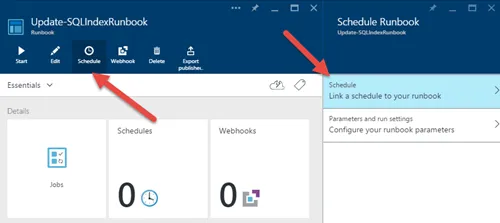
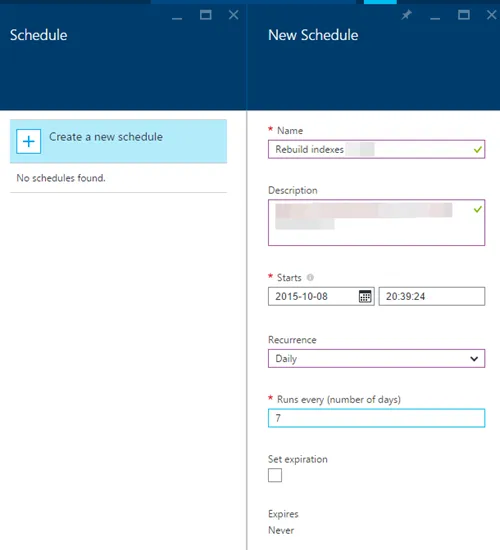
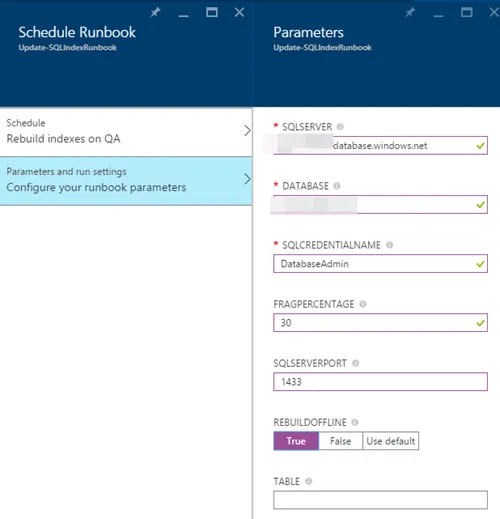
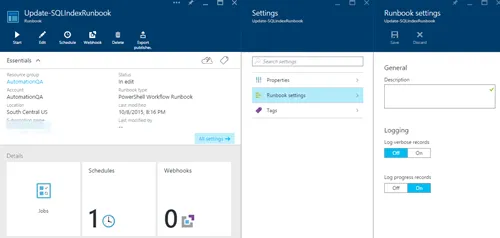
在本地 SQL 数据库中,经常会有一个维护计划,定期重建索引,尤其是在它没有太多使用时。如何在 Azure SQL DB 中设置呢?附注:我之前试过了,但由于找不到任何选项,我想也许他们会自动执行直到我读到这篇文章并进行了尝试:this post。
SELECT
DB_NAME() AS DBName
,OBJECT_NAME(ps.object_id) AS TableName
,i.name AS IndexName
,ips.index_type_desc
,ips.avg_fragmentation_in_percent
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.indexes i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), ps.object_id, ps.index_id, null, 'LIMITED') ips
ORDER BY ps.object_id, ps.index_id
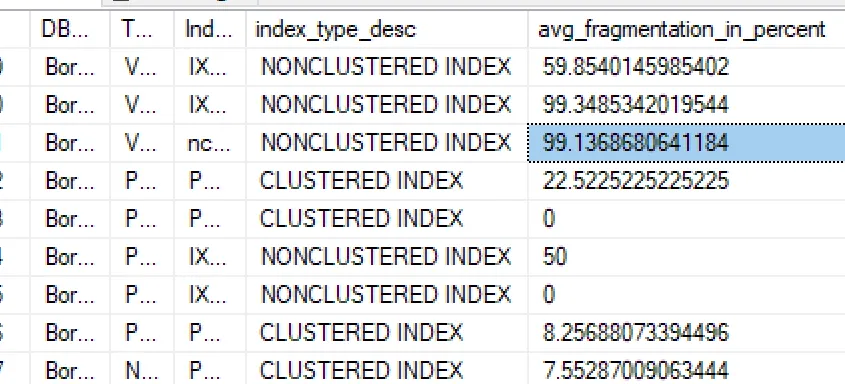
我发现我有需要维护的索引