我遇到了以下问题:
开始和结束的值在每隔一行中都会重复出现。我想用一个唯一的数字来标记它们,每次达到一个新的开始值时,该数字都会增加。
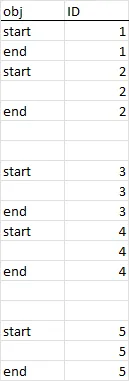
我还希望在 obj 列为空且不在开始和结束之间的行中,ID列保持为空。
非常感谢您提前的帮助!
可能有更简单的方式,但您可以使用cumsum()函数进行计算并添加一些逻辑。
library(dplyr)
library(tidyr)
x <- c("start", "end", NA)
df <- tibble(obj = x[c(1, 2, 1, 3, 2, 3, 3, 1, 3, 2, 1, 3, 2, 3, 3, 1, 3, 2)])
df %>%
mutate(ID = cumsum(replace_na(obj == "start", 0)),
ID = if_else(ID == cumsum(replace_na(obj == "end", 0)) & is.na(obj), NA_integer_, ID))
# A tibble: 18 x 2
obj ID
<chr> <int>
1 start 1
2 end 1
3 start 2
4 NA 2
5 end 2
6 NA NA
7 NA NA
8 start 3
9 NA 3
10 end 3
11 start 4
12 NA 4
13 end 4
14 NA NA
15 NA NA
16 start 5
17 NA 5
18 end 5
rle和一些cumsum来实现。rl <- rle(dat$obj)
nid <- rl$values == '' & cumsum(rl$values == 'start') == cumsum(rl$values == 'end')
rl$values <- cumsum(rl$values == 'start')
rl$values[nid] <- ''
transform(dat, ID=rep(rl$values, rl$lengths))
# obj ID
# 1 start 1
# 2 end 1
# 3 start 2
# 4 2
# 5 end 2
# 6
# 7
# 8 start 3
# 9 3
# 10 end 3
# 11 start 4
# 12 4
# 13 end 4
# 14
# 15
# 16 start 5
# 17 5
# 18 end 5
数据:
dat <- structure(list(obj = c("start", "end", "start", "", "end", "",
"", "start", "", "end", "start", "", "end", "", "", "start",
"", "end")), row.names = c(NA, -18L), class = "data.frame")