我正在尝试通过产品名称匹配两个列表。
这些产品来自不同的网站,它们的名称可能有许多微妙的变化,例如“iPhone 128 GB”与“Apple iPhone 128GB”。
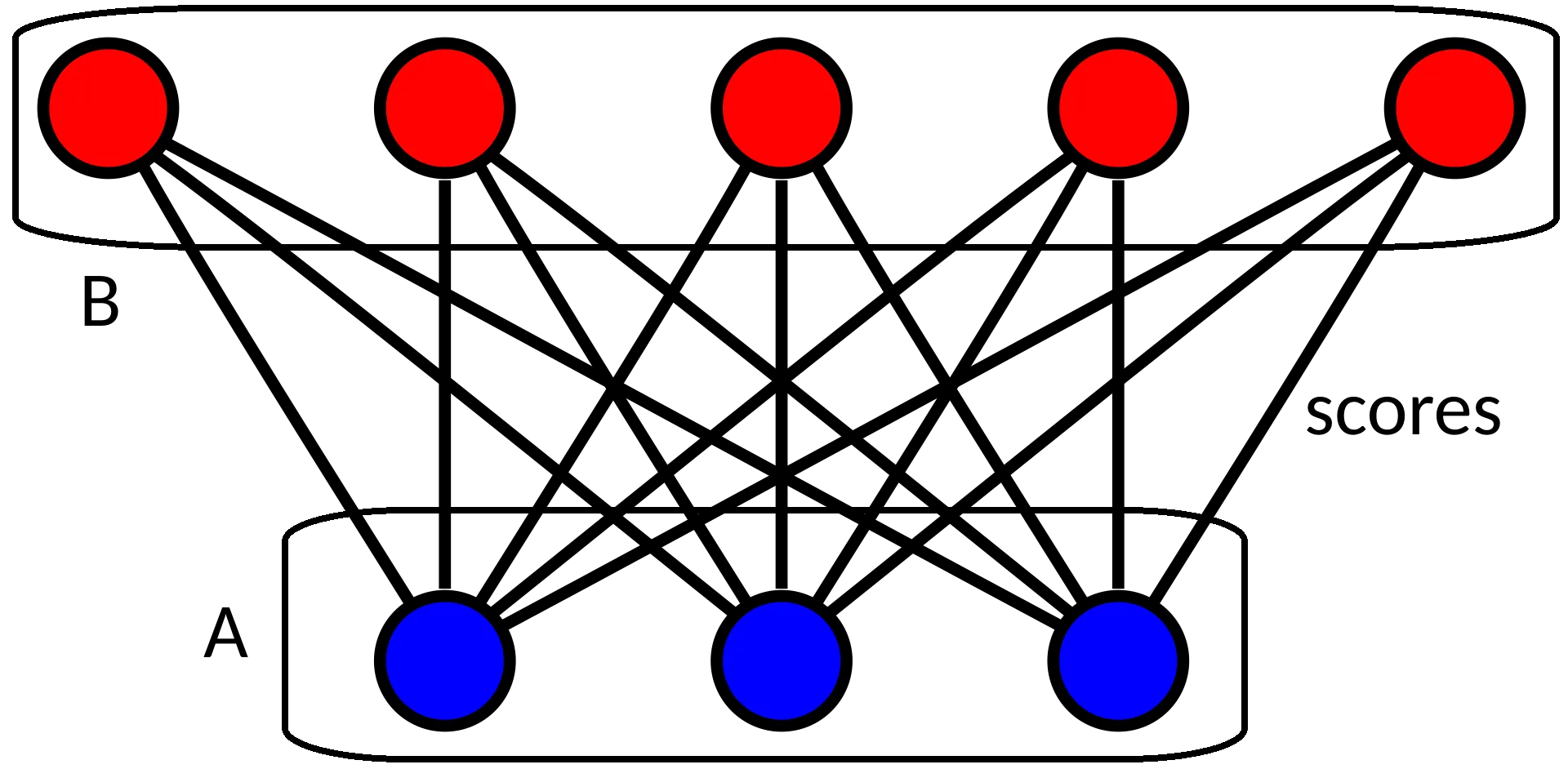
这些产品列表相交,但不相等,并且一个列表也不是另一个列表的超集;即一些来自列表A的产品不在列表B中,反之亦然。
给定一个比较两个字符串(产品名称)并返回介于0和1之间的相似度得分的算法(我已经拥有了一个满意的实现),我正在寻找一种将列表A与列表B进行最优匹配的算法。
换句话说,我认为我正在寻找一种最大化匹配中所有相似分数总和的算法。
注意,一个列表中的产品最多只能与另一个列表中的一个产品匹配。
我的初始想法是,对于A中的每个产品,获取其与B中每个产品的相似度,并保留得分最高的产品,前提是它超过某个阈值,例如0.75。匹配这些产品。如果得分最高的产品已经在循环中的先前迭代中与A中的另一个产品匹配,请选择第二高的产品,前提是它超过上述阈值。等等。
我的担忧是,如果在后面的循环中有更好的匹配,但是来自B的产品在前面的迭代中已经分配给A中的另一个产品,则匹配不是最佳的。
为确保将产品与其最高相似度对应的产品配对,我想到了以下实现:
预先计算所有A-B对的相似度得分
丢弃低于上述阈值的相似性
按相似度排序,从高到低
对于每个对,如果A和B中的产品均未被匹配,请匹配这些产品。这个算法应该优化地匹配产品对,确保每对产品都获得最高的相似度。
我的担忧是,它非常耗费计算和内存资源:假设我有5000个产品在两个列表中,那就是要预先计算并且潜在地存储(或在数据库中)25,000,000个相似度得分;尽管由于所需的最小阈值而实际上会更少,但仍可能非常大,并且仍然需要大量的CPU资源。
我是否漏掉了什么?
这些产品来自不同的网站,它们的名称可能有许多微妙的变化,例如“iPhone 128 GB”与“Apple iPhone 128GB”。
这些产品列表相交,但不相等,并且一个列表也不是另一个列表的超集;即一些来自列表A的产品不在列表B中,反之亦然。
给定一个比较两个字符串(产品名称)并返回介于0和1之间的相似度得分的算法(我已经拥有了一个满意的实现),我正在寻找一种将列表A与列表B进行最优匹配的算法。
换句话说,我认为我正在寻找一种最大化匹配中所有相似分数总和的算法。
注意,一个列表中的产品最多只能与另一个列表中的一个产品匹配。
我的初始想法是,对于A中的每个产品,获取其与B中每个产品的相似度,并保留得分最高的产品,前提是它超过某个阈值,例如0.75。匹配这些产品。如果得分最高的产品已经在循环中的先前迭代中与A中的另一个产品匹配,请选择第二高的产品,前提是它超过上述阈值。等等。
我的担忧是,如果在后面的循环中有更好的匹配,但是来自B的产品在前面的迭代中已经分配给A中的另一个产品,则匹配不是最佳的。
为确保将产品与其最高相似度对应的产品配对,我想到了以下实现:
预先计算所有A-B对的相似度得分
丢弃低于上述阈值的相似性
按相似度排序,从高到低
对于每个对,如果A和B中的产品均未被匹配,请匹配这些产品。这个算法应该优化地匹配产品对,确保每对产品都获得最高的相似度。
我的担忧是,它非常耗费计算和内存资源:假设我有5000个产品在两个列表中,那就是要预先计算并且潜在地存储(或在数据库中)25,000,000个相似度得分;尽管由于所需的最小阈值而实际上会更少,但仍可能非常大,并且仍然需要大量的CPU资源。
我是否漏掉了什么?
有没有更高效的算法可以得到与这个改进版本相同的输出?